


Retrieval-Augmented Generation, kurz RAG, ist eine der praktischsten Methoden, um LLM-Anwendungen nützlicher zu machen. Nicht nur das interne Wissen des Modells nutzen — sondern Informationen abrufen und als Kontext in den Prompt injizieren.
Das funktioniert hervorragend, wenn Ihre Daten in einer lokalen Wissensdatenbank, einem Vektorspeicher oder einer Sammlung interner Dokumente vorhanden sind. Aber es gibt einen häufigen Haken: Ihr Wissen kann sehr leicht veraltet werden.
Wenn Ihre Anwendung aktuelle Informationen bereitstellen soll — zum Beispiel: Produktänderungen, Dokumentationsupdates, aktuelle Nachrichten oder Markttrends — dann ist ein statischer Index meist nicht ausreichend. Sie brauchen eine Möglichkeit, aktuelle Informationen abzurufen, bevor Sie die API aufrufen.
Genau hier wird eine suchbasierte Retrieval-Schicht nützlich.
In diesem Tutorial zeige ich, wie man Bright Datas SERP API in Python nutzt, um frische Suchergebnisse abzurufen und sie in eine leichtgewichtige Retrieval-Schicht für einen RAG-Workflow zu verwandeln. Das Ziel ist nicht, ein riesiges Produktionssystem zu bauen, sondern eine saubere, praktische Pipeline zu erstellen, die die Kernidee klar demonstriert.
Warum statisches RAG nicht immer ausreicht
Ein typisches RAG-Setup verwendet Embeddings und eine Vektordatenbank, um die relevantesten Chunks aus einer festen Dokumentensammlung abzurufen. Das ist großartig für Unternehmens-Wissensdatenbanken, Support-Inhalte, Verträge oder technische Dokumentation, die sich nicht stündlich ändert.
Aber viele reale Fragen sind zeitkritisch.
Stellen Sie sich einen Nutzer vor, der fragt:
- Was sind die neuesten Python-Bibliotheken für RAG?
- Was hat sich in der neuesten Version eines Frameworks geändert?
- Was gibt es Neues bei Browser-Automatisierungs-Tools?
- Was sind die aktuellsten Artikel zu einem bestimmten KI-Thema?
Wenn Ihre Retrieval-Schicht nur in einem alten lokalen Datensatz sucht, kann die Antwort unvollständig oder schlicht veraltet sein.
Ein flexiblerer Ansatz ist, Ihre RAG-Pipeline mit Live-Suchergebnissen anzureichern. Anstatt sich vollständig auf einen vorab erstellten Index zu verlassen, können Sie zunächst frische Informationen aus dem Web abrufen und diese dann in Kontext für das Modell umwandeln.
Das ist das Muster, das wir hier aufbauen werden.
Warum Bright Datas SERP API verwenden
Sie können natürlich versuchen, Suchergebnisse selbst zu scrapen. Aber das wird oft sehr schnell unübersichtlich. Suchmaschinen sind dynamisch, Strukturen ändern sich, und sobald Sie über ein Experiment hinausgehen, kämpfen Sie mit Zuverlässigkeitsproblemen statt mit Ihrer Anwendungslogik.
Deshalb ist die Verwendung einer dedizierten SERP API eine viel sauberere Wahl.
Bright Datas SERP API bietet programmatischen Zugriff auf Suchmaschinenergebnisse und ist damit gut geeignet für frischheitssensible RAG-Workflows. In diesem Tutorial verwende ich sie als Retrieval-Schicht, die relevante, aktuelle Such-Snippets in eine Python-Pipeline einspeist.
Das Schöne daran ist, dass man sich auf den Workflow selbst konzentrieren kann:
- Abfrage senden,
- Suchergebnisse empfangen,
- Ergebnisse in nutzbaren Kontext umwandeln,
- diesen Kontext in den LLM-Prompt einbetten.
Was wir bauen
Die Pipeline in diesem Artikel ist bewusst einfach gehalten:
- Ein Nutzer stellt eine Frage.
- Unser Python-Skript sendet eine Suchanfrage über Bright Datas SERP API.
- Wir sammeln die Top-organischen Ergebnisse.
- Wir wandeln Titel, Snippets und Quell-URLs in einen strukturierten Kontextblock um.
- Dieser Kontext kann dann an ein LLM zur Antwortgenerierung übergeben werden.
Das ist ein minimales, aber sehr praktisches Muster. Es ist besonders nützlich, wenn man die Einfachheit des suchgesteuerten Retrievals mit der Struktur eines RAG-Workflows kombinieren möchte.
Die API-Anfrage in Python einrichten

Der erste Schritt ist, eine SERP-API-Zone in Bright Data zu erstellen und den API-Schlüssel zu erhalten. Sobald das erledigt ist, ist die Python-Seite unkompliziert.
Ich habe requests und Umgebungsvariablen verwendet, damit das Skript klein und einfach zu starten bleibt.
import os
import requests
from urllib.parse import quote_plus
API_URL = "https://api.brightdata.com/request"
def serp_search(query: str, zone: str, api_key: str, country: str = "us", language: str = "en") -> dict:
search_url = (
f"https://www.google.com/search"
f"?q={quote_plus(query)}&hl={language}&gl={country}"
)
payload = {
"zone": zone,
"url": search_url,
"format": "raw",
"data_format": "parsed_light"
}
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
response = requests.post(API_URL, headers=headers, json=payload, timeout=60)
print(f"HTTP status: {response.status_code}")
response.raise_for_status()
return response.json()
def print_top_results(data: dict, limit: int = 5) -> None:
organic = data.get("organic", [])[:limit]
if not organic:
print("Keine organischen Ergebnisse gefunden.")
print(data)
return
print("\nTop organische Ergebnisse:\n")
for idx, item in enumerate(organic, start=1):
title = item.get("title", "Kein Titel")
link = item.get("link", "Keine URL")
description = item.get("description", "Keine Beschreibung")
print(f"{idx}. {title}")
print(f" URL: {link}")
print(f" Snippet: {description}\n")
if __name__ == "__main__":
api_key = os.environ["BRIGHT_DATA_API_KEY"]
zone = os.environ["BRIGHT_DATA_SERP_ZONE"]
query = "best Python RAG libraries -site:reddit.com"
result = serp_search(query=query, zone=zone, api_key=api_key)
print_top_results(result)
Diese Funktion nimmt eine Suchanfrage, erstellt eine Google-Such-URL, sendet sie an Bright Data und gibt eine geparste Antwort mit den Top-organischen Ergebnissen zurück.
Zwei kleine Details sind hier wichtig.
Erstens: Der API-Schlüssel bleibt außerhalb des Codes, indem er aus einer Umgebungsvariable geladen wird. Das ist sicherer und sauberer als das Hardcoden von Credentials.
Zweitens: Ich verwende eine einfache Suchanfrage, die dem ähnelt, was ein echter Nutzer stellen könnte. In diesem Beispiel habe ich die Pipeline mit best Python RAG libraries -site:reddit.com getestet. Das ist eine gute Demo-Abfrage, weil sie breit genug ist, um mehrere relevante Ergebnisse zurückzugeben, und spezifisch genug, um zu zeigen, wie Such-Snippets zu Retrieval-Kontext werden können.
Die Top-Suchergebnisse ausgeben
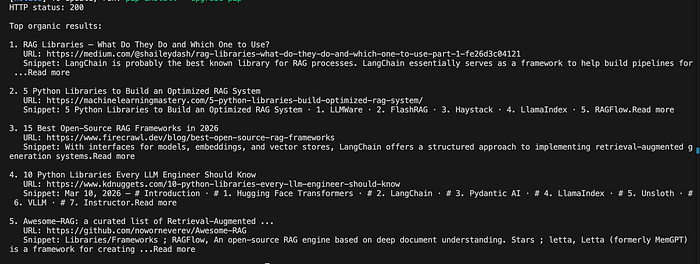
Sobald wir die API-Antwort haben, ist der nächste Schritt, die Top-organischen Ergebnisse zu inspizieren.
An diesem Punkt haben Sie bereits etwas Nützliches: frische Suchergebnisse kommen in einer strukturierten Form an, die Sie inspizieren, ranken, filtern oder transformieren können.
Das ist wichtig, weil ein Retrieval-Workflow nicht immer sofort vollständigen Seiteninhalt benötigt. In vielen Fällen sind Titel und Snippet bereits ausreichend, um zu identifizieren, ob eine Quelle relevant ist.
Suchergebnisse in RAG-Kontext umwandeln
Jetzt kommt der interessanteste Teil.
Anstatt bei rohen Suchergebnissen aufzuhören, können wir sie in einen Kontextblock umwandeln, der in einen LLM-Prompt injiziert werden kann. Das ist der Punkt, an dem Suche zu Retrieval wird.
Hier ist eine einfache Hilfsfunktion:
def build_rag_context(data: dict, limit: int = 5) -> str:
organic = data.get("organic", [])[:limit]
chunks = []
for idx, item in enumerate(organic, start=1):
title = item.get("title", "").strip()
snippet = item.get("description", "").strip()
link = item.get("link", "").strip()
chunk = f"[{idx}] {title}\n{snippet}\nQuelle: {link}"
chunks.append(chunk)
return "\n\n".join(chunks)
if __name__ == "__main__":
api_key = os.environ["BRIGHT_DATA_API_KEY"]
zone = os.environ["BRIGHT_DATA_SERP_ZONE"]
query = "best Python RAG libraries -site:reddit.com"
result = serp_search(query=query, zone=zone, api_key=api_key)
context = build_rag_context(result)
print("=== RAG KONTEXT ===\n")
print(context)
Das ist kein vollständiges vektorbasiertes Retrieval-System, aber es ist bereits ein bedeutungsvolles RAG-ähnliches Muster. Wir nehmen frische externe Informationen, strukturieren sie und bereiten sie für die nachgelagerte Generierung vor.
Der resultierende Kontext enthält einen Titel, ein kurzes Zusammenfassungs-Snippet und eine Quell-URL für jedes Ergebnis. Das ist genug, um eine LLM-Antwort in aktuellen, externen Informationen zu verankern, anstatt sich rein auf das Modellgedächtnis zu verlassen.
Warum dieses Muster nützlich ist
Was ich an diesem Ansatz mag, ist, dass er sowohl praktisch als auch erweiterbar ist.
Er ist praktisch, weil man ihn schnell aufbauen und sofort für frischheitssensible Aufgaben nutzen kann. Wenn Sie einen KI-Assistenten, einen Recherche-Helfer oder einen leichtgewichtigen Analyst-Workflow prototypisieren, ist das oft genug, um echten Mehrwert zu erzielen.
Er ist erweiterbar, weil diese einfache Version später aufgerüstet werden kann. Beispielsweise könnten Sie:
- Ergebnisse nach Domain filtern,
- Reranking hinzufügen,
- vollständigen Seiteninhalt von den Top-URLs abrufen,
- die abgerufenen Dokumente in Chunks aufteilen,
- die Ergebnisse in einer Vektordatenbank speichern,
- suchgesteuerte Retrieval mit Ihrer internen Wissensdatenbank kombinieren.
Mit anderen Worten: Dieses Tutorial gibt Ihnen den Frontend-Teil einer fortgeschritteneren RAG-Architektur, ohne Sie zu zwingen, mit unnötiger Komplexität zu beginnen.
Einschränkungen, die man beachten sollte
Dieses Muster ist nützlich, aber es lohnt sich, ehrlich über seine Grenzen zu sein.
Erstens sind Snippets nicht dasselbe wie vollständige Dokumente. Wenn Sie eine tiefe faktische Verankerung benötigen, sollten Sie wahrscheinlich später den vollständigen Inhalt ausgewählter Seiten abrufen und verarbeiten.
Zweitens hängt die Suchqualität immer noch von der Abfragequalität ab. Eine schwache Abfrage produziert schwaches Retrieval — Prompt-Engineering ist also nicht nur für die Generierung wichtig. Es spielt auch auf der Retrieval-Stufe eine Rolle.
Drittens ist Live-Retrieval von Natur aus dynamischer als die Arbeit mit einem eingefrorenen lokalen Index. Das ist der ganze Sinn, aber es bedeutet auch, dass man bei der Skalierung der Pipeline über Konsistenz, Caching und Kosten nachdenken sollte.
Trotzdem ist dieser Kompromiss für viele Anwendungsfälle genau das, was man möchte. Man opfert etwas Einfachheit im Austausch für frischeren Kontext und bessere Relevanz.
Fazit
Wenn Ihr RAG-Workflow auf aktuelle Informationen angewiesen ist, ist das Hinzufügen einer Live-Such-Schicht ein sehr natürlicher nächster Schritt.
In diesem Tutorial habe ich Bright Datas SERP API als Retrieval-Komponente in einer einfachen Python-Pipeline verwendet. Das Ergebnis ist ein leichtgewichtiges, aber effektives Muster: nach frischen Informationen suchen, sie in strukturierten Kontext umwandeln und diesen Kontext in Ihren LLM-Workflow einspeisen.
Das macht diesen Ansatz gut geeignet für KI-Anwendungen, die mehr als statisches Wissen benötigen.
Und das Beste daran ist vielleicht, dass man klein anfangen kann. Sie brauchen am ersten Tag keine vollständige Produktionsarchitektur. Ein kurzes Python-Skript, eine Suchanfrage und ein sauberer Kontext-Aufbaustep reichen bereits aus, um Ihre RAG-Pipeline deutlich aktueller zu machen.