

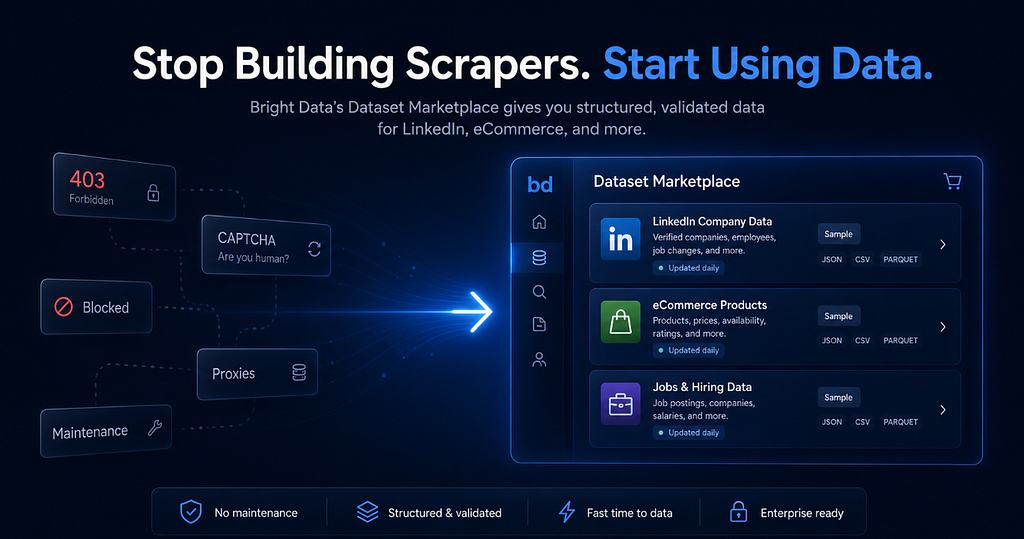
Eine praxisnahe Bewertung von Bright Data's Dataset Marketplace – und warum fertige LinkedIn- und E-Commerce-Datensätze wochenlange Scraping-Arbeit einsparen können
Das Sammeln öffentlicher Daten aus Quellen wie LinkedIn, E-Commerce-Websites, Jobbörsen und Firmenverzeichnissen beginnt oft als einfache technische Aufgabe. Man definiert die Zielfelder, schreibt einen Scraper, parst das HTML und speichert die Ergebnisse.
In der Praxis kann dieser Prozess jedoch schnell schwer zu warten werden. Website-Strukturen ändern sich, Anfragen können blockiert oder mit Rate-Limiting versehen werden, Felder erscheinen inkonsistent auf verschiedenen Seiten, und die Rohdaten müssen oft bereinigt, validiert und dedupliziert werden, bevor sie für Analysen, maschinelles Lernen, Marktforschung oder RAG-Pipelines nützlich sind.
Für viele Teams ist das Hauptziel nicht die Wartung von Scraping-Infrastruktur. Das Ziel ist der Zugang zu zuverlässigen, strukturierten Daten, die im weiteren Verlauf genutzt werden können.
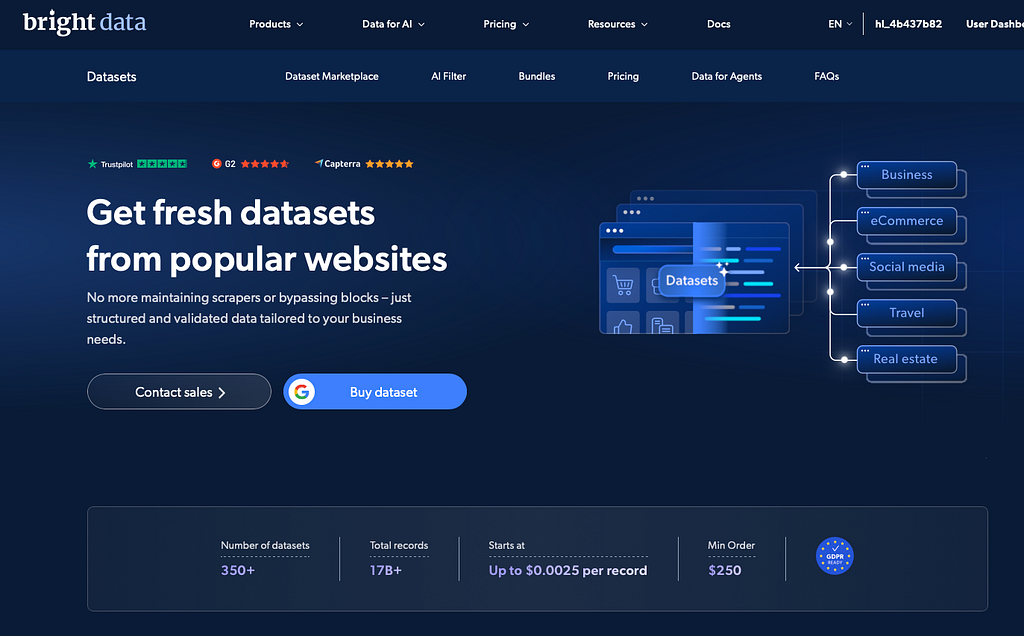
Bright Data's Dataset Marketplace ist für genau diese Art von Workflow konzipiert. Er bietet gebrauchsfertige öffentliche Web-Datensätze aus Quellen wie LinkedIn, E-Commerce-Plattformen, sozialen Medien, Jobbörsen und mehr. Diese Datensätze sind strukturiert, dokumentiert und vor dem Download auswertbar.
Dieser Artikel erklärt, wann ein fertiger Datensatz ein besserer Ausgangspunkt sein kann als ein selbst gebauter Scraper, wie man Datensätze im Bright Data's Dataset Marketplace bewertet, und wann benutzerdefiniertes Scraping dennoch die richtige Wahl sein kann.
Das Problem: „Einfach scrapen" ist selten einfach

Einen Prototyp-LinkedIn-Scraper zu bauen ist einfach, aber die eigentlichen Probleme erscheinen meist, wenn man ihn in Produktion bringt.
Zunächst sieht die Aufgabe unkompliziert aus: öffentliche Firmenprofile sammeln, Felder wie Firmenname, Branche, Standort, Website, Mitarbeiterzahl und Beschreibung extrahieren, dann die Ergebnisse für Analyse, Anreicherung oder eine ML-Pipeline speichern.
Die erste Version sieht vielleicht so aus:
import requests
from bs4 import BeautifulSoup
url = "https://example.com/product-page"
html = requests.get(url).text
soup = BeautifulSoup(html, "html.parser")
print(soup.title.text)
Das funktioniert wunderbar in Tutorials. Dann versucht man es auf einer echten Website: JavaScript-gerenderte Seiten, HTML das von DevTools abweicht, fehlende Felder, blockierte Anfragen, inkonsistente Layouts, unordentliche Daten und ein Scraper, der heute funktioniert, aber morgen versagt.
Zu diesem Zeitpunkt beginnt das „kleine Skript" sich in Infrastruktur zu verwandeln. Man fügt Wiederholungsversuche, Logging, Proxy-Rotation, Browser-Automatisierung, Schema-Validierung, Deduplizierung, Speicherung und Monitoring hinzu. Dann fragt jemand:
„Können wir das wöchentlich aktualisieren?"
Und plötzlich ist das kein schnelles Skript mehr. Es ist eine Pipeline, die man besitzt.
Dieses Eigentum hat seinen Preis.
Die echten Kosten eines selbst gebauten Scrapers
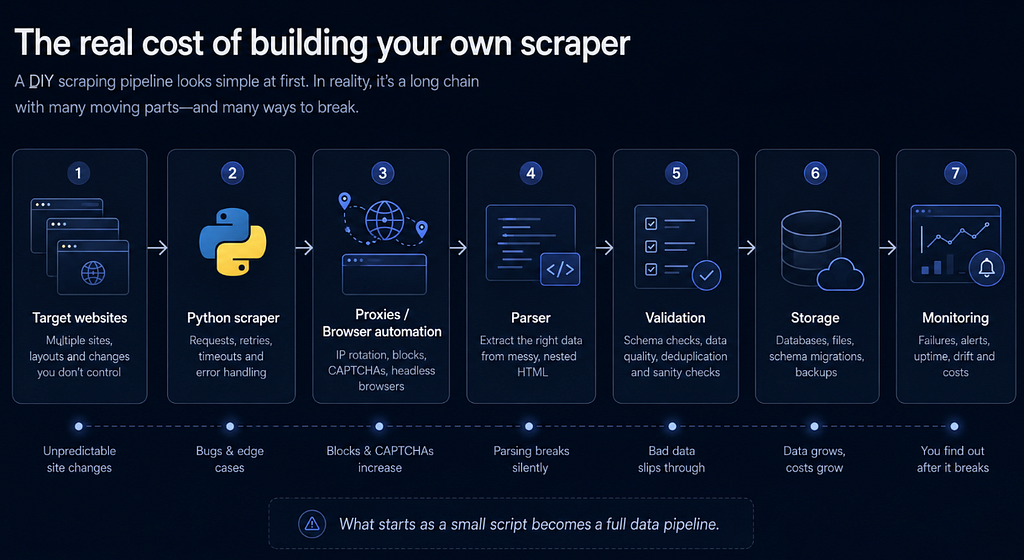
Was als einfacher Scraper beginnt, kann schnell zu einer vollständigen Datenerfassungs-Pipeline mit eigenem Wartungsaufwand werden.
Eine produktionsreife LinkedIn-Datenpipeline erfordert in der Regel mehr als Extraktionslogik. Sie muss blockierte Anfragen, JavaScript-Rendering, inkonsistente Layouts, fehlende Felder, duplizierte Datensätze, Datenvalidierung, Speicherung, Monitoring und laufende Wartung bewältigen.
Das sind die echten Kosten des selbst gebauten Scrapers. Das anfängliche Skript mag klein sein, aber die umgebende Infrastruktur kann deutlich mehr Zeit kosten als die Extraktionslogik selbst.
Ein produktionsreifer Scraper benötigt in der Regel mehr als Extraktionslogik. Er braucht:
- Handhabung blockierter Anfragen;
- Umgang mit JavaScript-Rendering;
- Parsing inkonsistenter Layouts;
- Validierung von Feldern;
- Deduplizierung und Normalisierung von Datensätzen;
- Speicherung der Daten an einem nützlichen Ort;
- Aktualisierung von Datensätzen;
- Monitoring und Behebung von Fehlern bei Website-Änderungen.
Und das schließt noch nicht einmal die Zeit ein, die damit verbracht wird zu verstehen, ob die gesammelten Daten tatsächlich nutzbar sind. Für Data Engineering, ML, Analytics, Marktforschung und RAG-Systeme sind rohe gescrapte HTML-Daten selten das Endergebnis.
Das nützliche Ergebnis ist strukturiertes Datenmaterial.
Mein LinkedIn-Scraper-Problem
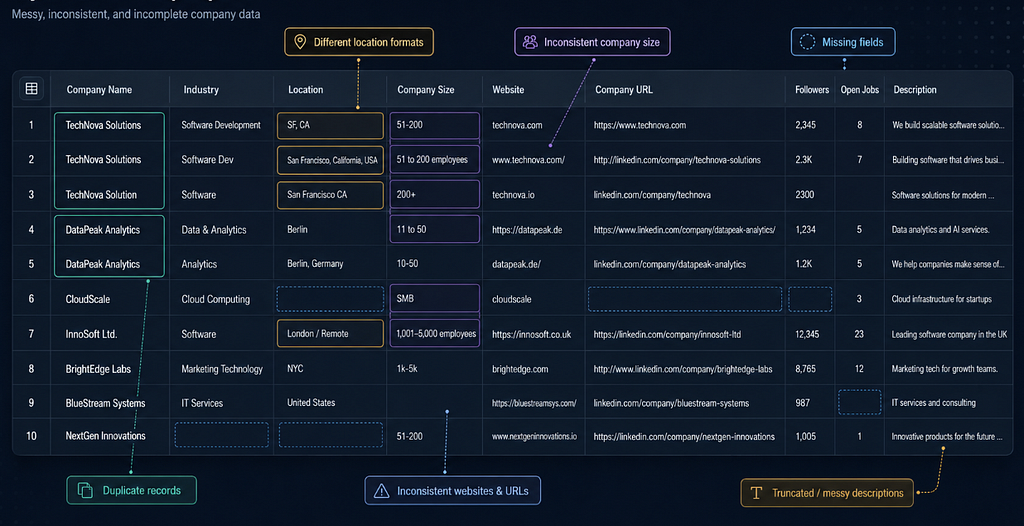
Stell dir vor, du benötigst öffentliche Firmendaten für ein Marktforschungsprojekt. Vielleicht brauchst du Felder wie Firmenname, Branche, Standort, Unternehmensgröße, Website, LinkedIn-URL, Followerzahl, Stellenangebote, öffentliche Beiträge, Beschreibung und mitarbeiterbezogene Signale.
Nach einigen Stunden beginnen die schwierigeren Fragen. Das Schema muss stabil bleiben, fehlende Felder müssen behandelt, Standorte normalisiert, Unternehmen dedupliziert und alte Datensätze aktualisiert werden. Und das alles, ohne ein fragiles System zu bauen, das jedes Mal bricht, wenn sich die Website ändert.
Hier wird das „Ich kann es selbst scrapen"-Denken teuer.
Denn der Scraper ist nicht das finale Ergebnis.
Das finale Ergebnis ist ein zuverlässiger Datensatz.
Bright Data's LinkedIn-Datensätze umfassen Profile, Unternehmen, Jobs und Beiträge, mit über 899 Millionen verfügbaren Datensätzen in JSON, NDJSON, JSON Lines, CSV und Parquet.
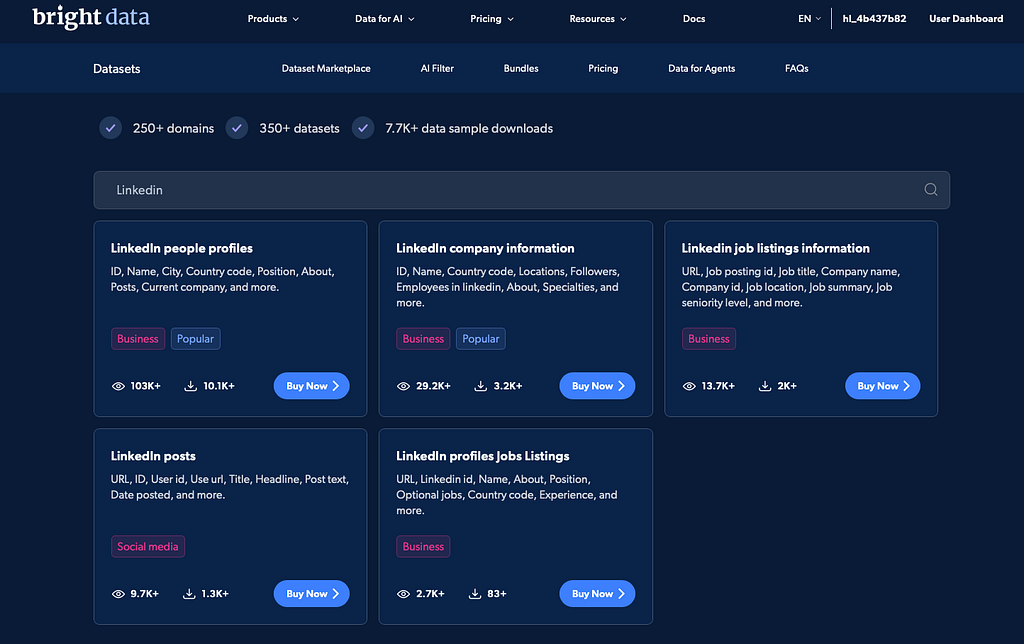
Das ist ein völlig anderer Ausgangspunkt als ein fragiler lokaler Scraper.
Statt zu fragen „Wie sammle ich all das?" kann man anfangen zu fragen: „Welche Felder brauche ich, wie aktuell müssen die Daten sein und wie integriere ich sie in meine Pipeline?" Das ist eine viel bessere technische Diskussion.
Das gleiche Problem gibt es bei E-Commerce-Daten
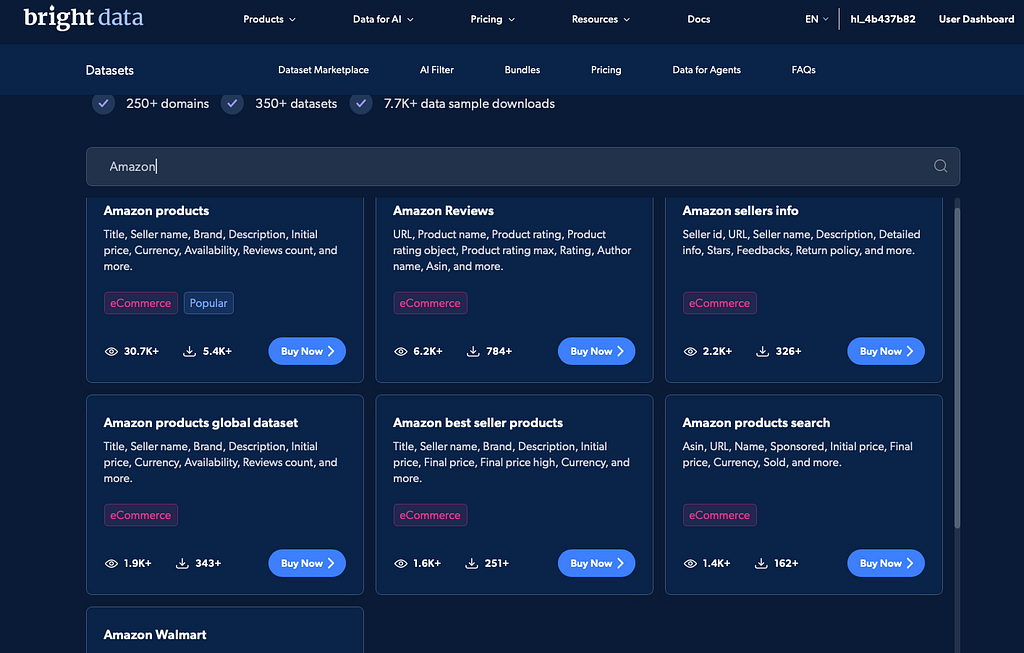
E-Commerce-Scraping wirkt zunächst unkompliziert, aber Produktions-Workflows erfordern oft mehr als das Extrahieren von Feldern aus einer Produktseite. Produktdaten können Preise, Verfügbarkeit, Bewertungen, Rezensionen, Verkäuferdetails, Varianten, Bilder, Beschreibungen und Versandinformationen umfassen.
Bright Data's E-Commerce-Datensätze umfassen Produktdaten, Preise, Verfügbarkeit, Bewertungen, Kundenfeedback und Verkäuferdetails über 216 Datensätze und mehr als 9 Milliarden Datensätze.
Für Wettbewerbspreisgestaltung, Produktintelligenz, Sortimentsanalyse, Bewertungsauswertung und Marktforschung hilft diese Art strukturierter Daten Teams, weniger Zeit mit der Wartung von Erfassungslogik zu verbringen und mehr Zeit damit, mit den Daten selbst zu arbeiten.
Was Bright Data's Dataset Marketplace bietet
Bright Data's Dataset Marketplace umfasst über 250 Domains mit regelmäßig aktualisierten Datensätzen aus öffentlich verfügbaren Informationen. Man kann Datensätze direkt entdecken, filtern, anpassen und kaufen.
Einfach gesagt, hilft es dabei, die schmerzhaftesten Teile der Web-Datenerfassung zu überspringen:
Website-Zugang
→ Extraktion
→ Bereinigung
→ Strukturierung
→ Validierung
→ Lieferung
Statt mit rohem HTML zu beginnen, startet man mit strukturierten Datensätzen. Das ist der Kernwert. Der Marketplace verschiebt den Ausgangspunkt der Pipeline: statt rohem HTML beginnt man mit validierten, strukturierten Datensätzen.
Ein Datensatz kann inspiziert, gefiltert, gesampelt, heruntergeladen und in eine Pipeline integriert werden.
Bright Data unterstützt JSON, NDJSON, CSV, XLSX und Parquet, mit Lieferoptionen wie Snowflake, Webhook, Google Cloud, E-Mail, Pub/Sub, Amazon S3, SFTP und Azure.

Für Data Engineers bestimmt das Format, wie schnell ein Datensatz in den Rest des Stacks gelangt.
Warum das für ML und RAG wichtig ist
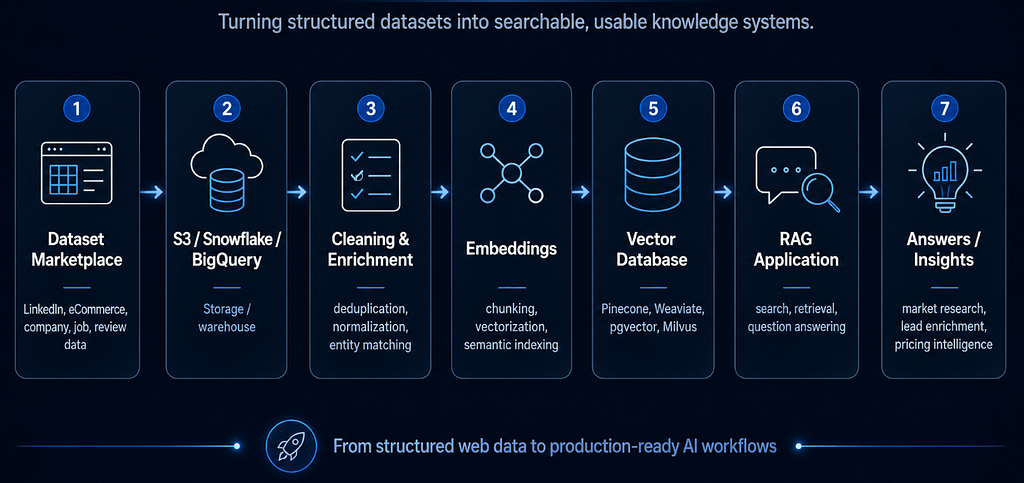
Viele moderne Datenprojekte sind keine einfachen Dashboards mehr. Es sind ML-Pipelines, RAG-Anwendungen, interne Forschungsassistenten, Preisüberwachungssysteme, Lead-Scoring-Modelle und Marktüberwachungstools. Bei diesen Systemen ist der Engpass oft nicht das Modell.
Der Engpass ist oft die Datenqualität. Schwache, veraltete oder inkonsistente Daten führen zu schlechten RAG-Antworten, unordentlichen ML-Mustern und Analytics-Dashboards, denen die Leute irgendwann nicht mehr vertrauen.
Deshalb können vorgefertigte und validierte Datensätze wertvoll sein. Sie helfen dabei, sich auf die Teile zu konzentrieren, die tatsächlich Geschäftswert schaffen:
- Bereinigungsregeln spezifisch für die eigene Domain;
- Anreicherung;
- Entity-Matching;
- Embeddings;
- Retrieval-Qualität;
- Modellbewertung;
- Analytics;
- Entscheidungsfindung.
Mit anderen Worten: weniger Zeit damit verbringen, gegen Websites zu kämpfen, und mehr Zeit damit, das Produkt zu bauen.
Ein praktischer Workflow: wie ich den Dataset Marketplace nutzen würde
Hier ist der Workflow, den ich als Data Engineer befolgen würde.
Schritt 1: Nach dem Datensatz suchen
Ich würde damit beginnen, im Marketplace nach der benötigten Datenquelle zu suchen: öffentliche LinkedIn-Firmendaten, Stellenangebote, öffentliche Beiträge, Amazon- oder Walmart-Produktdaten, E-Commerce-Bewertungen, Unternehmensdatensätze oder Immobiliendaten.
In dieser Phase kaufe ich noch nichts. Ich prüfe, ob der Datensatz existiert und ob er meinem Anwendungsfall nahekommt.
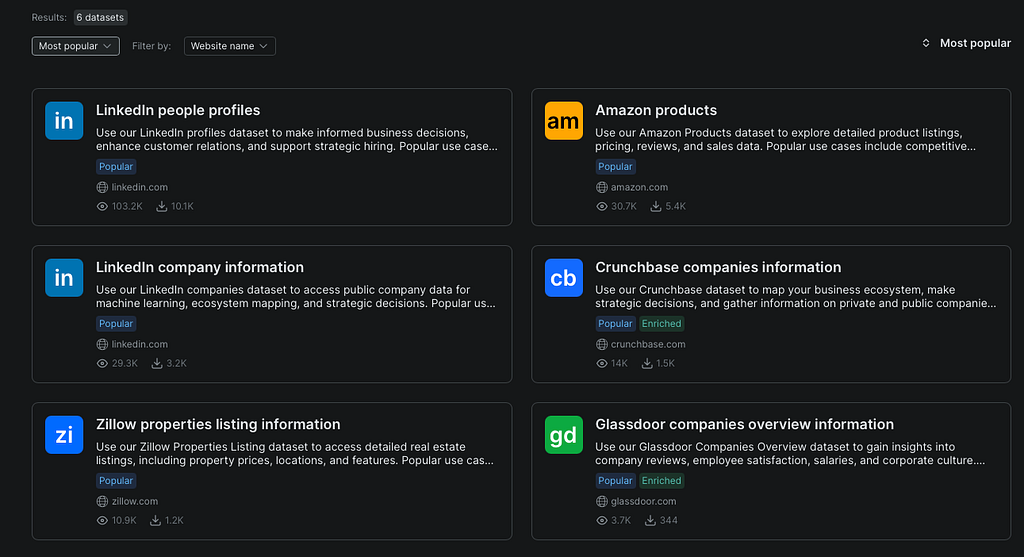
Schritt 2: Das Schema inspizieren
Das ist der wichtigste Schritt. Bevor ich über die Datensatzmenge nachdenke, möchte ich die Felder verstehen. Ein riesiger Datensatz ist nutzlos, wenn er nicht die benötigten Spalten enthält. Also würde ich Feldnamen, Datentypen, Pflicht- und optionale Felder, Zeitstempel, Quell-URLs, IDs, verschachtelte Strukturen, Standorte und Produkt- oder Unternehmenskennzeichnungen prüfen.
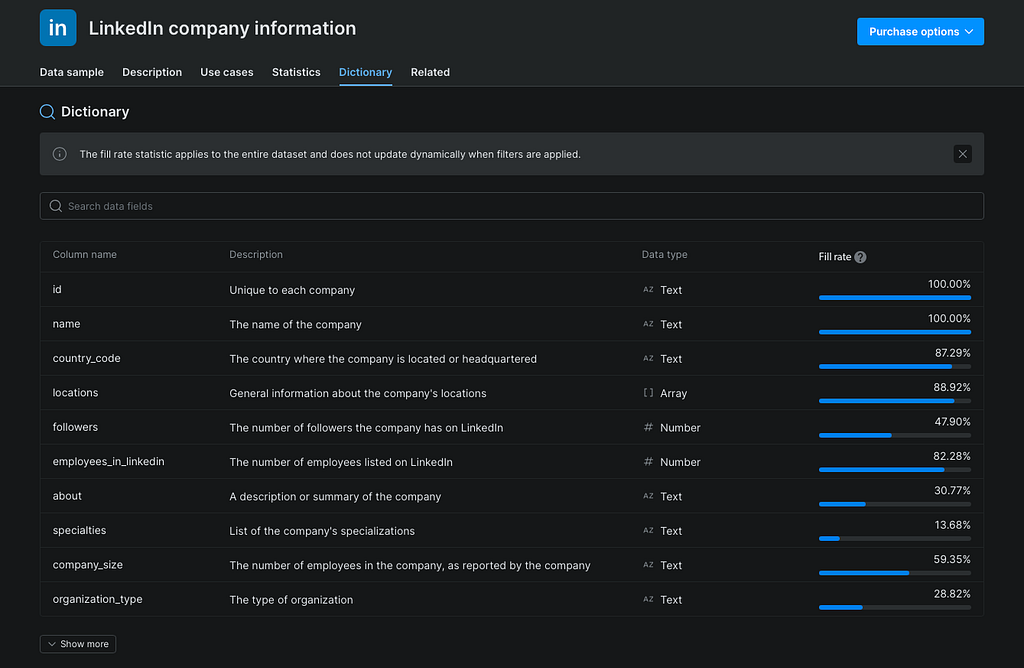
Vor der Nutzung eines Datensatzes möchte ich die tatsächlichen Felder, Datentypen, Beschreibungen und Füllraten sehen.
Hier verhindert man zukünftige Probleme. Schlechte Datenentscheidungen beginnen meist mit dem Überspringen der Schema-Inspektion.
Schritt 3: Ein Sample herunterladen
Ich würde niemals eine echte Pipeline um einen Datensatz herum entwerfen, ohne vorher ein Sample zu betrachten. Ein Sample hilft mir zu prüfen, ob Felder befüllt sind, Null-Werte akzeptabel sind, Standorte normalisiert sind, Kategorien nützlich sind, URLs gültig sind, Duplikate handhabbar sind und die Struktur einfach in pandas, Spark, DuckDB, Snowflake oder BigQuery ladbar ist.

Schritt 4: Den Datensatz filtern
Die meisten Teams brauchen nicht „alles". Sie brauchen eine fokussierte Teilmenge: Unternehmen in einem bestimmten Land, Jobs mit bestimmten Titeln, Produkte in einer Kategorie, kürzlich aktualisierte Datensätze, Artikel über einem Bewertungsschwellenwert, Verkäufer von einem bestimmten Marketplace oder Unternehmen in einer bestimmten Branche.
Felder und Filter können über die Benutzeroberfläche oder API angepasst werden, um den Datensatz auf die benötigte Teilmenge einzugrenzen.
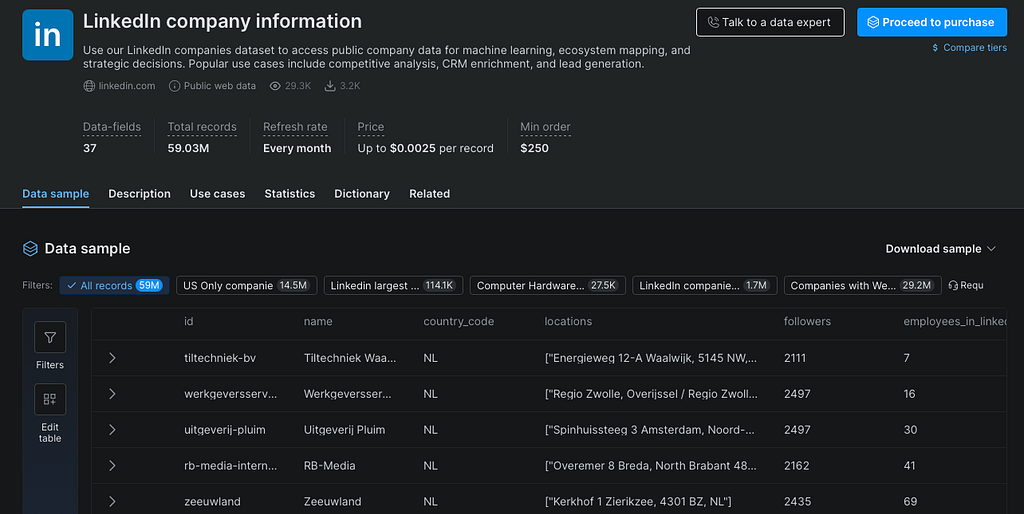
Das ist ein weiterer großer Unterschied zum DIY-Scraping: Mit dem eigenen Scraper erfolgt das Filtern oft nach der Erfassung; mit einem Marketplace-Datensatz kann man oft vor der Einspeisung filtern. Das kann Speicherplatz, Verarbeitungszeit und Kosten sparen.
Schritt 5: Das Lieferformat wählen
CSV funktioniert für lokale Analysen, JSON oder NDJSON für Backend-Pipelines, Parquet für Analytics- und ML-Workflows und Cloud-Lieferung für Produktionsdatenplattformen. Für größere Analytics-Datensätze wäre mein Standard Parquet: kompakt, spaltenbasiert und kompatibel mit modernen Daten-Tools.
Der Data-Engineering-Vergleich
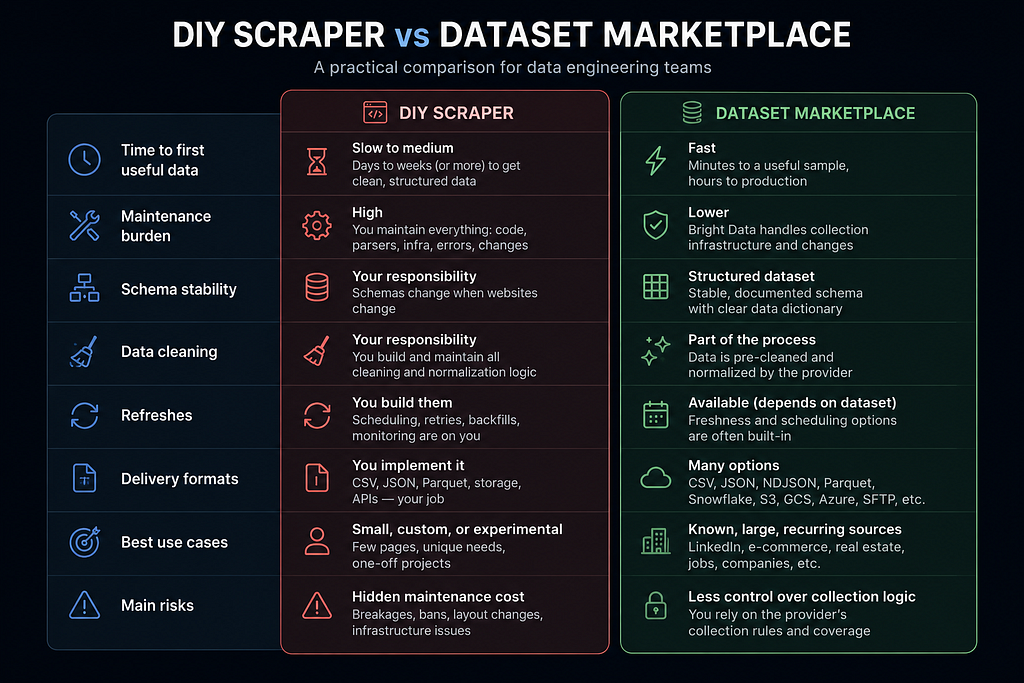
Das ist der einfachste Weg, wie ich darüber nachdenke. Das Bauen eines eigenen Scrapers gibt einem maximale Kontrolle: Man entscheidet, was gesammelt wird, wie es geparst wird, wie oft es aktualisiert wird und wie der finale Datensatz aussehen soll.
Aber diese Kontrolle kommt mit Verantwortung. Man besitzt die Extraktionslogik, Proxies, Wiederholungsversuche, Fehler, Bereinigung, Schema-Stabilität, Aktualisierungen, Lieferformate und jeden zukünftigen Fix, wenn etwas kaputtgeht.
Das ist in Ordnung für kleine, benutzerdefinierte oder experimentelle Aufgaben. Wenn ich ein paar hundert Datensätze von einer einfachen öffentlichen Website brauche, werde ich wahrscheinlich den Scraper selbst schreiben. Aber sobald das Projekt größer wird, ändert sich der Kompromiss. Wenn ich strukturierte LinkedIn-ähnliche oder E-Commerce-Daten benötige und Wert auf Qualität, Aktualität und Lieferformate lege, möchte ich nicht den Großteil meiner Zeit mit der Wartung von Scraping-Infrastruktur verbringen.
Der Dataset Marketplace tauscht Low-Level-Sammlungskontrolle gegen einen schnelleren Weg zu nutzbaren Daten.
Wann ich immer noch einen eigenen Scraper bauen würde
Ich denke nicht, dass Engineers vollständig aufhören sollten, Scraper zu bauen. Es gibt immer noch gute Gründe, einen eigenen zu bauen: die Website ist einfach und stabil, der Datensatz ist klein, der Anwendungsfall ist hochgradig individuell, die Quelle ist intern, man benötigt Echtzeit-Interaktion oder man braucht Felder, die in keinem bestehenden Datensatz verfügbar sind.
Für Millionen strukturierter Datensätze aus LinkedIn- oder E-Commerce-Quellen, mit Aktualisierungen und stabilen Lieferformaten, lohnt es sich zu prüfen, ob der Datensatz bereits existiert, bevor man Code schreibt.
Wo der Dataset Marketplace am besten passt
Meiner Meinung nach ist Bright Data's Dataset Marketplace am nützlichsten für Teams, die an Marktforschung, Wettbewerbsintelligenz, E-Commerce-Analytics, Preisintelligenz, Lead-Anreicherung, Arbeitsmarktanalyse, ML- und RAG-Pipelines oder KI-Agenten arbeiten, die strukturierte öffentliche Web-Daten benötigen.
Das sind Fälle, in denen Datenqualität wichtiger ist als Scraping-Stolz. Das Ziel ist es, ein nützliches System zu bauen, nicht zu beweisen, dass man Daten manuell sammeln kann.
Ein realistisches Beispiel: RAG über Unternehmensdaten
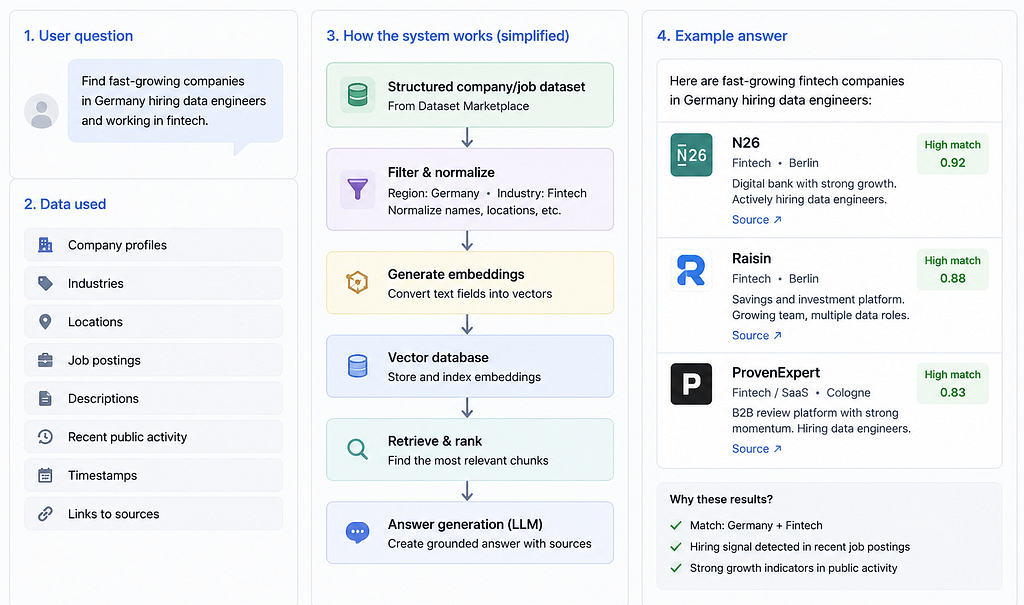
Stell dir vor, du möchtest einen internen Forschungsassistenten bauen. Ein Nutzer fragt:
„Finde schnell wachsende Unternehmen in Deutschland, die Data Engineers einstellen und im Fintech tätig sind."
Um das gut zu beantworten, benötigt das System möglicherweise Unternehmensprofile, Branchen, Standorte, Stellenangebote, Beschreibungen, aktuelle öffentliche Aktivitäten, Zeitstempel und Quell-Links. Man könnte Scraper für all das bauen, aber dann wartet man Datenerfassung, anstatt den Assistenten zu verbessern.
Ein besserer Workflow könnte sein:
- Mit einem strukturierten Unternehmens-/Job-Datensatz beginnen.
- Nach Region und Branche filtern.
- Firmennamen und Standorte normalisieren.
- Embeddings generieren.
- Daten in einer Vektordatenbank speichern.
- Retrieval- und Ranking-Logik aufbauen.
- Antwortqualität bewerten.
Das ist der Unterschied. Der Marketplace entfernt einen großen Teil des Low-Level-Erfassungsaufwands, damit man sich auf höherwertigere Arbeit konzentrieren kann.
Meine ehrliche Einschätzung
Nach der Arbeit mit Datenpipelines für eine Weile bin ich weniger beeindruckt von cleveren Scrapern und mehr beeindruckt von zuverlässigen Datenflüssen. Ein Scraper, der einmal funktioniert, reicht nicht aus. Ein strukturierter, dokumentierter, aktualisierbarer Datensatz, der einfach in den eigenen Stack geliefert werden kann, ist oft viel nützlicher.
Deshalb macht Bright Data's Dataset Marketplace für mich Sinn. Es ist keine Magie: Man muss immer noch das Schema inspizieren, das Sample validieren, den Anwendungsfall verstehen und Aktualität, Abdeckung und Datenqualität prüfen. Aber es ändert den Ausgangspunkt.
Fazit: Teure Arbeit nicht standardmäßig durchführen
Der eigentliche Fehler ist, standardmäßig einen Scraper zu bauen, bevor man prüft, ob ein fertiger Datensatz den Anwendungsfall bereits abdeckt.
Für LinkedIn-Daten, E-Commerce-Daten, Marktforschung, ML-Pipelines und RAG-Systeme sollte die erste Frage lauten:
„Existiert dieser Datensatz bereits?"
Wenn ja, und wenn Schema, Aktualität und Abdeckung den Anforderungen entsprechen, kann ein Marketplace-Datensatz die schnellere und zuverlässigere Option sein.
Scraper bauen, wenn individuelle Erfassung benötigt wird. Fertige Datensätze nutzen, wenn die Daten bereits existieren und das eigentliche Ziel Analyse, Intelligenz oder Produktentwicklung ist.
Nutzern ist nicht wichtig, wie ausgeklügelt der Scraper ist. Ihnen ist wichtig, ob das System nützliche Antworten liefert. Manchmal ist die beste technische Entscheidung, aufzuhören zu scrapen und anzufangen zu bauen.
Bright Data's Dataset Marketplace umfasst über 250 Domains, mit Datensätzen in JSON, CSV, Parquet und anderen Formaten. Wenn das Team Engineering-Zeit damit verbringt, bereits vorhandene Daten zu sammeln, sollte man den Marketplace erkunden oder ein kostenloses Sample herunterladen, um es gegen den eigenen Anwendungsfall zu testen.