


Ein Playwright-Skript, das auf einem Laptop gut funktioniert, kann unzuverlässig werden, sobald es in einen wiederkehrenden Scraping-Worker verwandelt wird. Nach dem Deployment sind die Probleme meist operativer Natur und nicht syntaktischer: Browser-Start in Containern, größere Images durch gebündelte Browser-Binaries, Proxy- und Credential-Verwaltung, Retry-Verhalten, überlappende geplante Läufe und JavaScript-gerenderte Seiten, die sich unter wiederholter Automatisierung anders verhalten.
Das verändert das Ziel. Die Herausforderung besteht nicht mehr nur darin, eine Seite zu öffnen und Daten einmalig zu extrahieren, sondern einen Worker zu bauen, der vorhersehbar läuft, sauber beendet und in ein Batch-Ausführungsmodell passt. Für diese Implementierung habe ich Playwright als Automatisierungsschicht behalten, Kubernetes Jobs und CronJobs für die Ausführung genutzt und mich über CDP mit einem Remote-Browser verbunden.
In diesem Artikel zeige ich eine praktische Version dieses Setups:
- Playwright als Automatisierungsschicht
- ein Remote-Browser-Backend für die Browser-Ausführung
- Kubernetes Jobs und CronJobs als Ausführungsmodell
Diese Kombination ist ein natürlicher Fit, weil ein Kubernetes Job für einmalige Aufgaben gedacht ist, die bis zur Fertigstellung laufen, während CronJob solche Jobs nach einem Zeitplan erstellt. Wenn überlappende Läufe riskant wären, unterstützt Kubernetes auch concurrencyPolicy: Forbid, um zu verhindern, dass ein neuer geplanter Lauf startet, während der vorherige noch aktiv ist.
Warum dieser Stack sinnvoll ist
Wenn Browser-Automatisierung vom lokalen Testing in eine wiederkehrende Scraping-Pipeline übergeht, wird der Browser selbst zu einem operativen Problem. Man öffnet nicht mehr nur eine Seite und extrahiert einmalig Daten. Man braucht einen Worker, der wiederholt laufen kann, JavaScript-lastige Ziele verarbeitet, Secrets aus dem Code heraushält und sauber unter einem Scheduler beendet.
Das verändert die Architekturfrage. Anstatt zu fragen: „Wie starte ich Chromium in diesem Container?", wird die nützlichere Frage: „Welche Teile der Browser-Ausführung sollte meine Workload selbst übernehmen, und welche delegiert werden?"
Für diese Implementierung habe ich einen Remote-Browser-Ansatz verwendet. Playwright blieb die Automatisierungsschicht, Kubernetes übernahm die Ausführung, und Bright Data Browser API stellte die verwaltete Browser-Session bereit, mit der sich der Worker über CDP verband.
Ich habe die Anwendung selbst sehr klein gehalten:
- Playwright über CDP mit Bright Data Browser API verbinden,
- eine JavaScript-gerenderte Seite öffnen,
- strukturierte Daten aus dem DOM extrahieren,
- den Worker in einen Container verpacken,
- als Kubernetes Job ausführen,
- dann dieselbe Worker-Definition in einen CronJob überführen.
Der erste Meilenstein war nicht „hat die Seite geöffnet", sondern „hat der Remote-Browser tatsächlich JavaScript-Inhalt gerendert und strukturierte Extraktionsausgabe zurückgegeben." In meinem Testlauf hat sich der Worker erfolgreich verbunden, eine Live-Inspektions-URL ausgegeben, https://quotes.toscrape.com/js/ geladen, 10 Zitat-Karten extrahiert und die ersten drei Zitate mit Autoren und Tags zurückgegeben. Das war der Moment, in dem das Setup aufgehört hat, theoretisch zu sein, und sich wie ein echter Scraping-Worker zu verhalten begann.
Schritt 1: Playwright mit Bright Data Browser API verbinden
Für die Remote-Browser-Schicht habe ich Bright Data Browser API verwendet. Es stellt eine verwaltete Browser-Session bereit, mit der Playwright über CDP verbunden werden kann — ein praktischer Fit für diesen Test.
Dies ist der kleinste nützliche Python-Worker, den ich verwendet habe:
import asyncio
import json
import os
from playwright.async_api import async_playwright
BROWSER_WS_ENDPOINT = os.environ["BROWSER_WS_ENDPOINT"]
TARGET_URL = os.getenv("TARGET_URL", "https://quotes.toscrape.com/js/")
async def main():
async with async_playwright() as p:
browser = await p.chromium.connect_over_cdp(BROWSER_WS_ENDPOINT)
try:
page = await browser.new_page()
client = await page.context.new_cdp_session(page)
frames = await client.send("Page.getFrameTree")
frame_id = frames["frameTree"]["frame"]["id"]
inspect = await client.send("Page.inspect", {"frameId": frame_id})
print("inspect_url:", inspect["url"])
await page.goto(TARGET_URL, timeout=120000)
await page.wait_for_load_state("networkidle")
quotes = await page.locator(".quote").evaluate_all(
"""elements => elements.map(el => ({
text: el.querySelector(".text")?.innerText ?? "",
author: el.querySelector(".author")?.innerText ?? "",
tags: Array.from(el.querySelectorAll(".tag")).map(t => t.innerText)
}))"""
)
result = {
"url": page.url,
"title": await page.title(),
"quotes_count": len(quotes),
"first_3_quotes": quotes[:3],
}
print(json.dumps(result, ensure_ascii=False, indent=2))
finally:
await browser.close()
if __name__ == "__main__":
asyncio.run(main())
Dies folgt dem dokumentierten Browser-API-Muster von Bright Data sehr genau: Verbindung mit Browser-API-Credentials herstellen, eine Seite erstellen, optional eine CDP-Session erstellen und dann den Remote-Browser zur Zielseite navigieren. Bright Datas eigene Beispiele zeigen auch Page.inspect zum Abrufen einer Live-Debugging-URL, und ihr Quick-Start-Guide rahmt Browser API ausdrücklich als Möglichkeit ein, eine echte Remote-Browser-Session für JavaScript-Rendering und interaktive Seiten zu starten.
Das erste Bemerkenswerte ist, dass dieser Code nicht den Bright-Data-API-Key-Flow verwendet, den andere Bright-Data-APIs nutzen. Browser-API-Authentifizierung verwendet die Browser-API-Zone-Credentials — konkret den Benutzernamen und das Passwort auf der Overview-Seite, keinen Bearer-API-Key. Diese Unterscheidung ist wichtig und leicht zu übersehen, wenn man zuvor Bright Datas REST-basierte APIs verwendet hat.
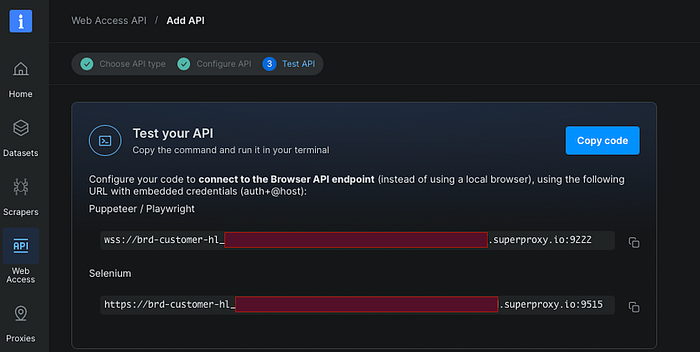
Schritt 2: Ein JavaScript-gerendertes Ziel validieren
Ich habe https://quotes.toscrape.com/js/ als Smoke-Test-Ziel verwendet. Bright Datas „erste Browser-Session"-Guide empfiehlt ausdrücklich JavaScript-basierte Seiten zur Validierung der Browser API und listet sogar quotes.toscrape.com/js/ unter den Beispielzielen auf.
Im erfolgreichen Lauf produzierte der Worker:
- eine Live-
inspect_url, - den erwarteten Seitentitel, Quotes to Scrape,
quotes_count: 10,- ein strukturiertes Array von Zitaten mit Autorennamen und Tags.
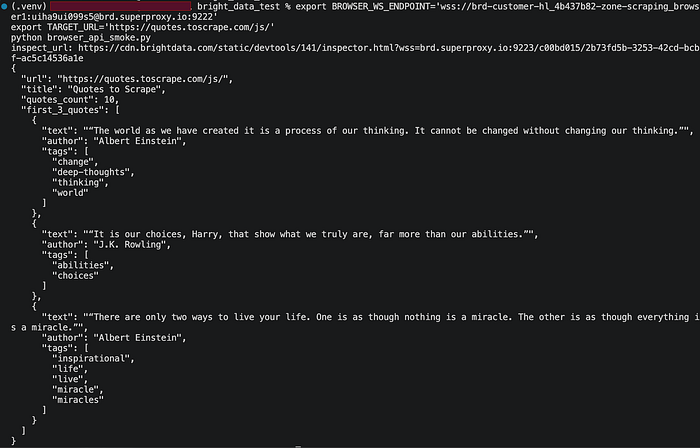
Dieses Ergebnis war aus zwei Gründen wichtig. Erstens zeigte es, dass die Browser-API-Verbindung selbst korrekt war. Zweitens zeigte es, dass dies kein oberflächlicher Konnektivitätstest war: Der Remote-Browser hatte die Seite vollständig gerendert und das DOM für die Extraktion verfügbar gemacht.
Schritt 3: Den Worker in einen Container verpacken
Das Container-Image blieb bewusst klein.
requirements.txt
playwright
Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY browser_api_smoke.py .
CMD ["python", "browser_api_smoke.py"]
Ein subtiler, aber wichtiger Punkt: Ich habe keine lokale Browser-Binary im Container installiert. Da Playwright sich über CDP mit einer Remote-Browser-Session verbindet, fungiert der Container als Control-Plane-Worker — nicht als der Ort, an dem der Browser selbst gestartet werden muss. Das hält das Image kleiner und das Laufzeitmodell sauberer.
Schritt 4: Den Browser-API-Endpunkt über ein Kubernetes Secret injizieren
Ich wollte, dass die Deployment-Schicht den Connection-String übernimmt, anstatt ihn in die Anwendung hardzucoden.
Der Worker erwartet eine einzige Umgebungsvariable: BROWSER_WS_ENDPOINT
Diese Variable enthält den vollständigen WebSocket-Endpunkt in der Form:
wss://USERNAME:[email protected]:9222
Dieser Ansatz hält den Anwendungscode stabil und verlagert das Credential-Management nach Kubernetes.
Schritt 5: Den Scraper als Kubernetes Job ausführen
Kubernetes Job ist die richtige Ressource, wenn man eine endliche Aufgabe haben möchte, die starten, ihre Arbeit erledigen und beenden soll. Das passt besonders gut zu Scraping-Workern, weil eine einzelne Scraping-Aufgabe oft konzeptionell eine Arbeitseinheit ist: dieses Ziel scrapen, Ausgabe emittieren, stoppen.
Hier ist das Manifest:
apiVersion: batch/v1
kind: Job
metadata:
name: browser-api-smoke
spec:
backoffLimit: 1
template:
spec:
restartPolicy: Never
containers:
- name: worker
image: browser-api-smoke:0.1
imagePullPolicy: IfNotPresent
env:
- name: BROWSER_WS_ENDPOINT
valueFrom:
secretKeyRef:
name: brightdata-browser
key: BROWSER_WS_ENDPOINT
- name: TARGET_URL
value: "https://quotes.toscrape.com/js/"
Für ein Produktions-Cluster sollte das image:-Feld auf ein echtes registry-gesichertes Image zeigen. Für ein Entwicklungs- oder Demo-Cluster funktioniert dieselbe Manifest-Form trotzdem.
In meinem Testlauf wurde der Job erfolgreich in 11 Sekunden abgeschlossen. Die Logs zeigten die Live-Inspektions-URL und den erwarteten extrahierten Payload, einschließlich 10 Zitate und der ersten drei Zitat-Objekte. Das beweist den gesamten Pfad: Kubernetes Pod → Playwright-Worker → Bright Data Browser API → Remote-Rendering → strukturierte Extraktion.
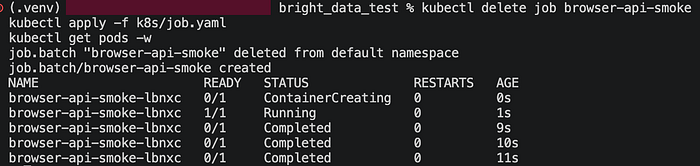
Schritt 6: Denselben Worker in einen CronJob überführen
Sobald der einmalige Job erfolgreich war, war der nächste Schritt, ihn zu planen.
Kubernetes CronJob erstellt Job-Ressourcen nach einem wiederkehrenden Zeitplan. Für Scraping-Pipelines ist das nützlich für wiederkehrende Erfassungen wie tägliche Snapshots, Preischecks oder Verfügbarkeitsmonitoring. Kubernetes unterstützt auch concurrencyPolicy, und Forbid ist ein sehr sinnvoller Standard, wenn man keine überlappenden Läufe gegen dasselbe Ziel möchte.
Hier ist die geplante Version:
apiVersion: batch/v1
kind: CronJob
metadata:
name: browser-api-smoke-cron
spec:
schedule: "*/5 * * * *"
concurrencyPolicy: Forbid
successfulJobsHistoryLimit: 2
failedJobsHistoryLimit: 2
jobTemplate:
spec:
backoffLimit: 1
template:
spec:
restartPolicy: Never
containers:
- name: worker
image: browser-api-smoke:0.1
imagePullPolicy: IfNotPresent
env:
- name: BROWSER_WS_ENDPOINT
valueFrom:
secretKeyRef:
name: brightdata-browser
key: BROWSER_WS_ENDPOINT
- name: TARGET_URL
value: "https://quotes.toscrape.com/js/"
Das Wichtige ist, dass sich der Anwendungscode überhaupt nicht geändert hat. Derselbe Worker lief zuerst als Job und dann als CronJob. Das ist ein guter Indikator dafür, ob die Scraping-Logik tatsächlich deployment-freundlich ist.
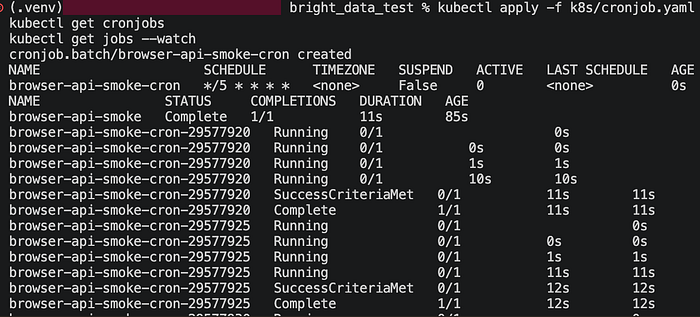
Was in der Praxis wirklich wichtig war
Drei operative Details erwiesen sich als wichtiger als der eigentliche Python-Code.
1. Browser-API-Credentials sind nicht dasselbe wie API-Key-Auth
Wenn man bereits mit Bright-Data-APIs gearbeitet hat, ist es sehr leicht anzunehmen, dass sich alles mit einem API-Key authentifiziert. Browser API funktioniert nicht so. Es verwendet Browser-API-Zone-Credentials — konkret den Benutzernamen und das Passwort, die im Overview-Tab der Zone sichtbar sind. Bright Datas Browser-API-Dokumentation ist diesbezüglich eindeutig.
2. CDP gibt mehr als nur Navigation
connect_over_cdp() zu verwenden bedeutet nicht nur, sich mit dem Remote-Browser zu verbinden. Es ermöglicht auch, eine CDP-Session zu erstellen und Protokollmethoden direkt aufzurufen. Playwright dokumentiert diesen rohen CDP-Zugriff über CDPSession.send, und Bright Datas eigene Beispiele verwenden ihn, um eine Inspektions-URL über Page.inspect zu generieren. Das machte das Debugging der Remote-Session viel konkreter als ein einfacher Black-Box-Request/Response-Workflow.
3. Jobs sind der richtige Standard für Browser-Worker
Eine scraping Browser-Session ist normalerweise eine begrenzte Arbeitseinheit, kein dauerhaft laufender Service. Kubernetes Job passt von Natur aus zu dieser Form. Pod starten, Skript ausführen, Ergebnis emittieren, sauber beenden. Dann zu CronJob wechseln, wenn man geplante Wiederholung möchte. Das eigene Workload-Modell von Kubernetes unterstützt diese Trennung stark.
Ergebnisse
Der finale erfolgreiche Lauf lieferte folgende Ausgabe:
{
"url": "https://quotes.toscrape.com/js/",
"title": "Quotes to Scrape",
"quotes_count": 10,
"first_3_quotes": [
{
"text": "\u201cThe world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.\u201d",
"author": "Albert Einstein",
"tags": ["change", "deep-thoughts", "thinking", "world"]
},
{
"text": "\u201cIt is our choices, Harry, that show what we truly are, far more than our abilities.\u201d",
"author": "J.K. Rowling",
"tags": ["abilities", "choices"]
},
{
"text": "\u201cThere are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.\u201d",
"author": "Albert Einstein",
"tags": ["inspirational", "life", "live", "miracle", "miracles"]
}
]
}
Fazit
Der Hauptwert dieses Setups besteht darin, Browser-basiertes Scraping in ein saubereres Produktionsmodell zu verwandeln.
Playwright bleibt auf Automatisierung und Extraktion fokussiert. Kubernetes stellt das Batch-Ausführungsmodell bereit. Bright Data Browser API dient als Remote-Browser-Schicht, die das gesamte Design einfacher zu betreiben macht — besonders wenn die Workload mit JavaScript-Rendering, wiederkehrenden geplanten Läufen und Produktionszuverlässigkeit umgehen muss.
In der Praxis verwandelt das den Scraper von einem fragilen Skript in einen Worker mit einem klaren Laufzeitvertrag: verbinden, rendern, extrahieren, sauber beenden und bei Bedarf erneut ausführen. Das ist der Punkt, an dem Bright Data in dieser Implementierung den größten Mehrwert gebracht hat — nicht durch Änderung der Scraping-Logik selbst, sondern indem es die Browser-Seite des Systems einfacher zu verwalten machte.
Sobald derselbe Playwright-Worker zuverlässig mit Bright Data Browser API funktionierte und dann sauber als Kubernetes Job und CronJob lief, hörte die Pipeline auf, experimentell zu wirken, und begann sich deploybar anzufühlen.