

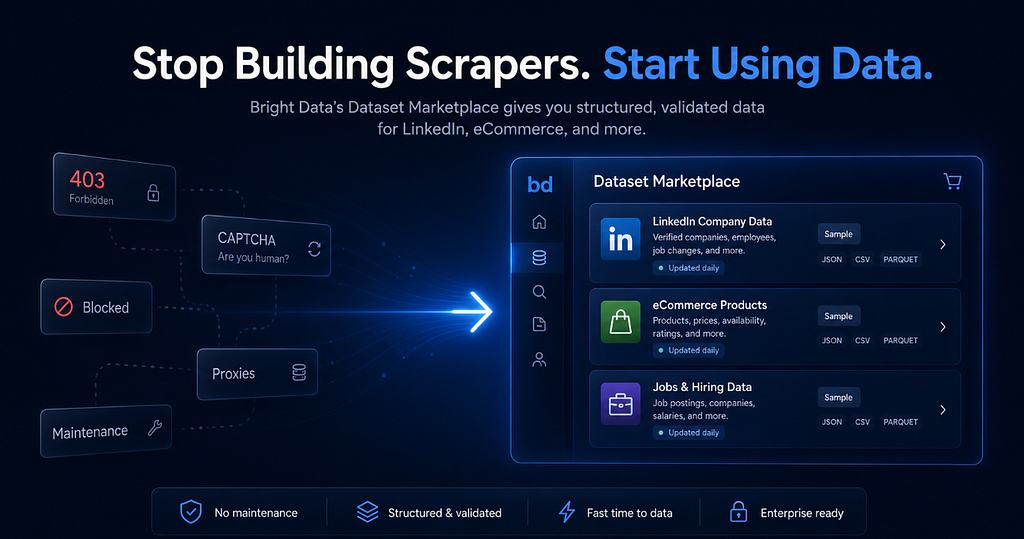
A practical data engineer's review of Bright Data's Dataset Marketplace - and why ready-made LinkedIn and e-commerce datasets can save weeks of scraping work
Collecting public data from sources such as LinkedIn, e-commerce websites, job boards, and company directories often starts as a simple engineering task. You define the target fields, write a scraper, parse the HTML, and store the results.
In practice, however, this process can quickly become difficult to maintain. Website structures change, requests may be blocked or rate-limited, fields can appear inconsistently across pages, and the raw output often requires cleaning, validation, and deduplication before it is useful for analytics, machine learning, market research, or RAG pipelines.
For many teams, the main goal is not to maintain scraping infrastructure. The goal is to access reliable, structured data that can be used downstream.
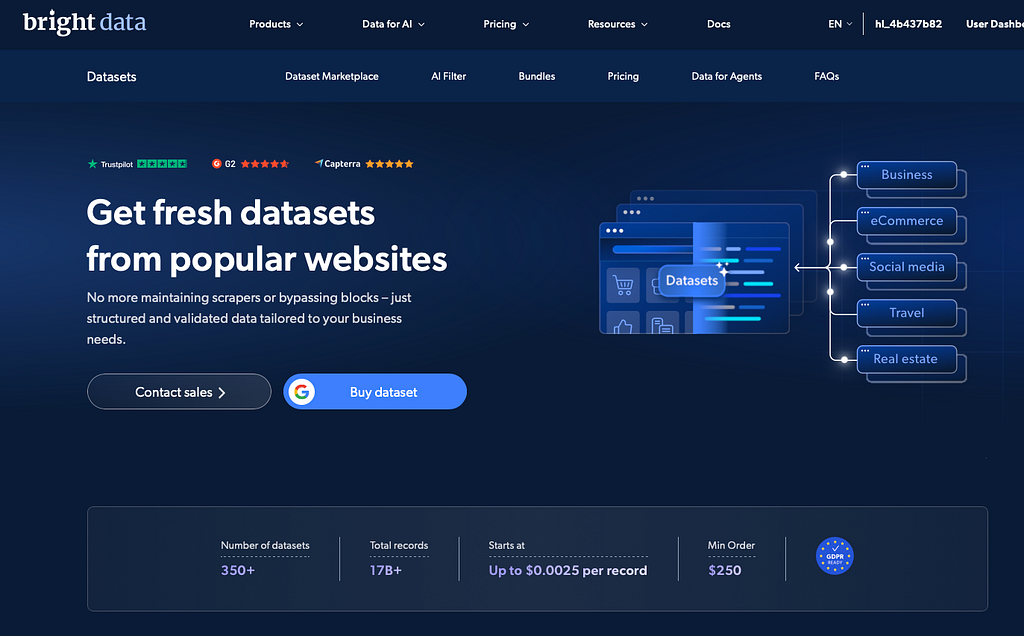
Bright Data's Dataset Marketplace is designed for this type of workflow. It provides ready-to-use public web datasets from sources such as LinkedIn, e-commerce platforms, social media, job boards, and more. These datasets are structured, documented, and available to evaluate before download.
This article explains when a ready-made dataset can be a better starting point than building a scraper from scratch, how to evaluate datasets in Bright Data's Dataset Marketplace, and when custom scraping may still be the right choice.
The problem: "just scrape it" is rarely just scraping

Building a prototype LinkedIn scraper is easy, but the real problems usually appear when you push it to production.
At first, the task looks straightforward: collect public company profiles, extract fields such as company name, industry, location, website, employee count, and description, then save the results for analysis, enrichment, or a machine learning pipeline.
The first version may look simple:
import requests
from bs4 import BeautifulSoup
url = "https://example.com/product-page"
html = requests.get(url).text
soup = BeautifulSoup(html, "html.parser")
print(soup.title.text)
This works beautifully in tutorials. Then you try it on a real website: JavaScript-rendered pages, HTML that differs from DevTools, missing fields, blocked requests, inconsistent layouts, messy data, and a scraper that works today but fails tomorrow.
At that point, your "small script" starts turning into infrastructure. You add retries, logging, proxy rotation, browser automation, schema validation, deduplication, storage, and monitoring. Then someone asks:
"Can we refresh this every week?"
And suddenly this is no longer a quick script. It is a pipeline you own.
That ownership has a cost.
The real cost of building your own scraper
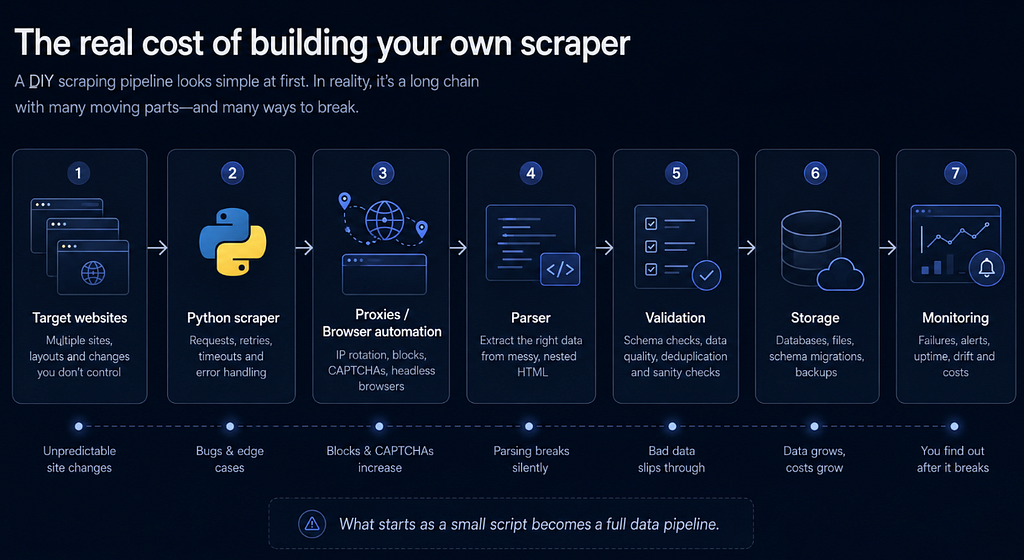
What begins as a simple scraper can quickly become a full data collection pipeline with its own maintenance burden.
A production-ready LinkedIn data pipeline usually requires more than extraction logic. It needs to handle blocked requests, JavaScript rendering, inconsistent layouts, missing fields, duplicated records, data validation, storage, monitoring, and ongoing maintenance.
That is the real cost of building the scraper yourself. The initial script may be small, but the surrounding infrastructure can take significantly more time than the extraction logic itself.
A production-ready scraper usually needs more than extraction logic. It needs:
- Handling blocked requests;
- Dealing with JavaScript rendering;
- Parsing inconsistent layouts;
- Validating fields;
- Deduplicating and normalizing records;
- Storing the data somewhere useful;
- Refreshing records;
- Monitoring and fixing failures when websites change.
And this does not even include the time spent understanding whether the collected data is actually usable. For data engineering, ML, analytics, market research, and RAG systems, raw scraped HTML is rarely the final asset.
The useful asset is structured data.
My LinkedIn scraper problem
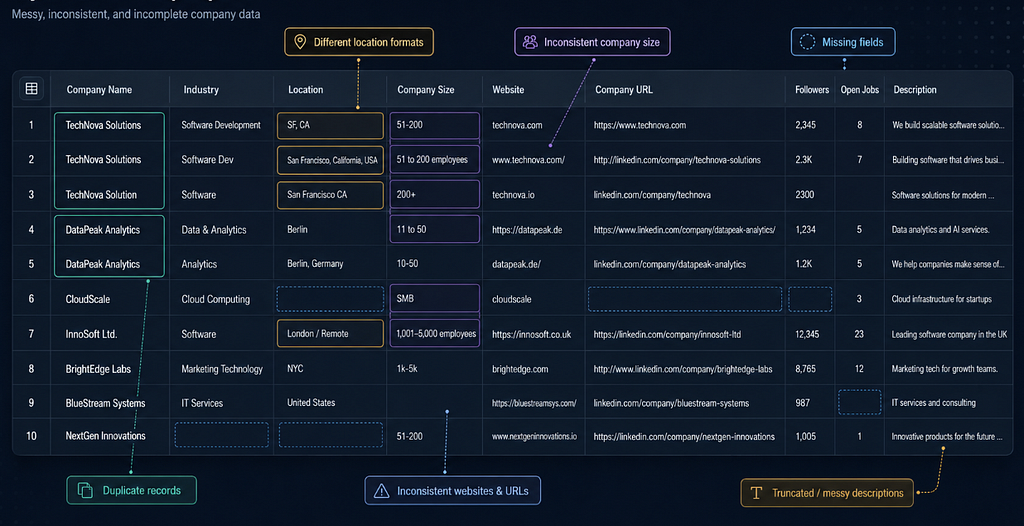
Imagine you need public company information for a market research project. You may need fields like company name, industry, location, company size, website, LinkedIn URL, follower count, job postings, public posts, description, and employee-related signals.
After a few hours, the harder questions start. I need to keep the schema stable, handle missing fields, normalize locations, deduplicate companies, refresh old records, and make the data usable for analysts, ML engineers, and downstream pipelines, without building a fragile system that breaks every time the website changes.
This is where the "I can scrape it myself" mindset becomes expensive.
Because the scraper is not the final deliverable.
The final deliverable is a reliable dataset.
Bright Data's LinkedIn datasets cover profiles, companies, jobs, and posts, with 899M+ records available in JSON, NDJSON, JSON Lines, CSV, and Parquet.
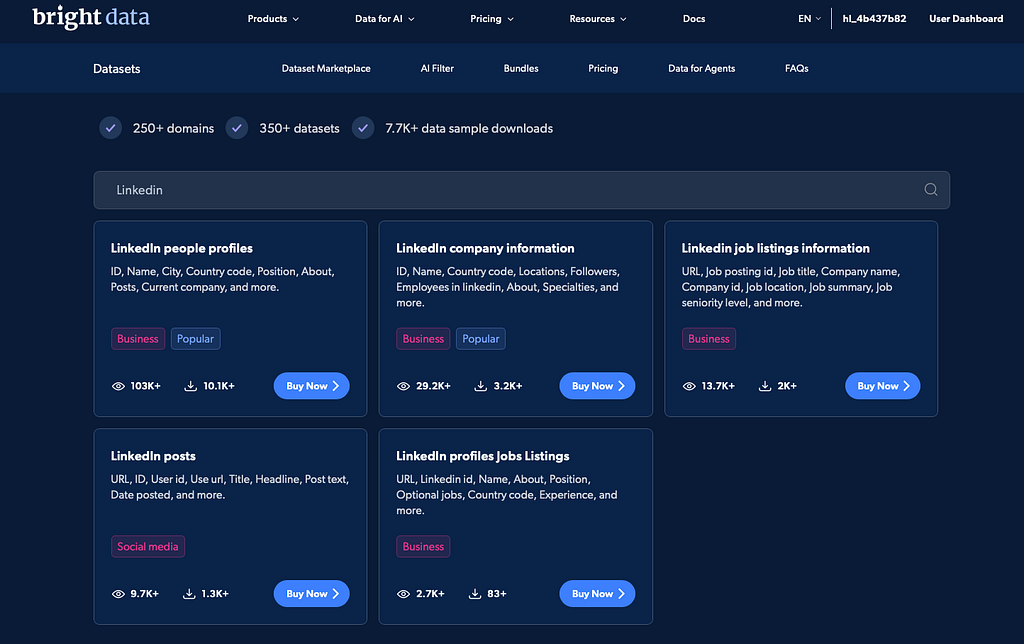
That is a very different starting point from a fragile local scraper.
Instead of asking "How do I collect all of this?", you can start asking: "Which fields do I need, how fresh should the data be, and how do I plug it into my pipeline?". That is a much better engineering conversation.
The same problem exists in e-commerce data
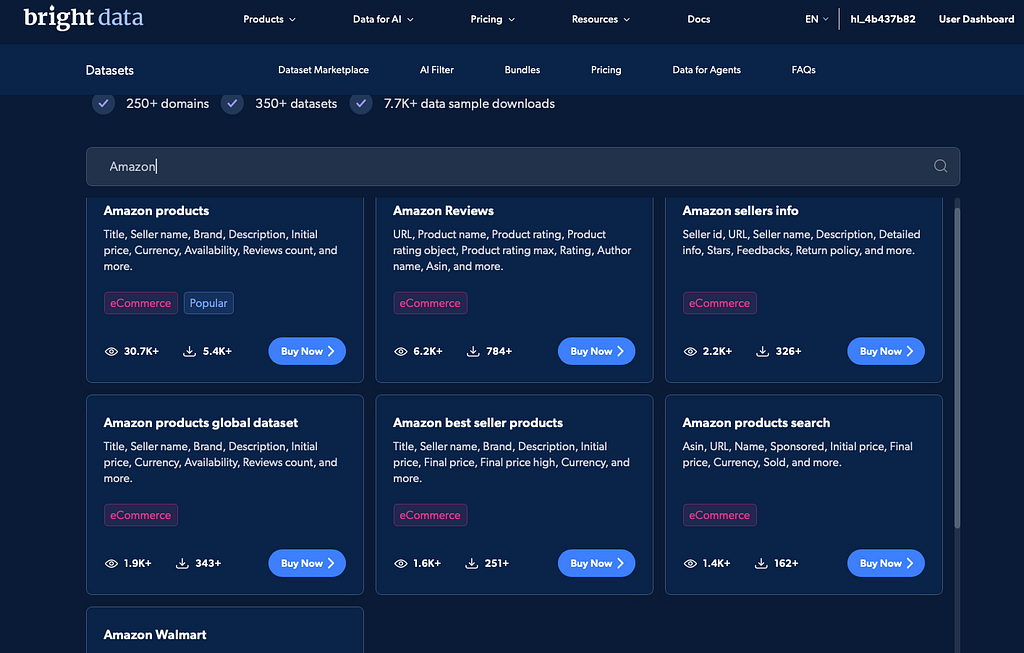
E-commerce scraping looks straightforward at first, but production workflows often require more than extracting fields from a product page. Product data may include pricing, availability, ratings, reviews, seller details, variants, images, descriptions, and shipping information.
Bright Data's e-commerce datasets cover product data, pricing, availability, ratings, reviews, customer feedback, and seller details across 216 datasets and 9B+ records.
For competitive pricing, product intelligence, assortment analysis, review mining, and market research, this kind of structured data helps teams spend less time maintaining collection logic and more time working with the data itself.
What Bright Data's Dataset Marketplace gives you
Bright Data's Dataset Marketplace covers 250+ domains with regularly updated datasets sourced from publicly available information. You can discover, filter, customize, and purchase datasets directly.
In simple terms, it helps you skip the most painful parts of web data collection:
website access
→ extraction
→ cleaning
→ structuring
→ validation
→ delivery
Instead of starting with raw HTML, you start with structured records. That is the core value. The marketplace shifts where your pipeline begins: instead of raw HTML, you start with validated, structured records.
A dataset can be inspected, filtered, sampled, downloaded, and integrated into a pipeline.
Bright Data supports JSON, NDJSON, CSV, XLSX, and Parquet, with delivery options including Snowflake, Webhook, Google Cloud, Email, Pub/Sub, Amazon S3, SFTP, and Azure.

For data engineers, format determines how fast a dataset moves into the rest of the stack.
Why this matters for ML and RAG
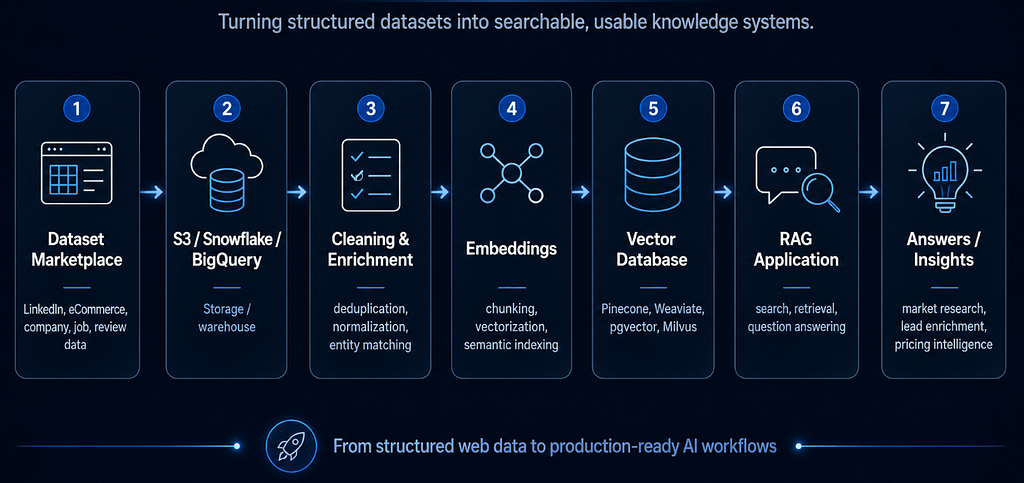
A lot of modern data projects are not just dashboards anymore. They are ML pipelines, RAG applications, internal research assistants, pricing intelligence systems, lead scoring models, and market monitoring tools. For these systems, the bottleneck is often not the model.
The bottleneck is often data quality. Weak, outdated, or inconsistent data leads to weak RAG answers, messy ML patterns, and analytics dashboards people eventually stop trusting.
That is why pre-collected and validated datasets can be valuable. They help you focus on the parts that actually create business value:
- Cleaning rules specific to your domain;
- Enrichment;
- Entity matching;
- Embeddings;
- Retrieval quality;
- Model evaluation;
- Analytics;
- Decision-making.
In other words, you spend less time fighting websites and more time building the product.
A practical workflow: how I would use Dataset Marketplace
Here is the workflow I would follow as a data engineer.
Step 1: Search for the dataset
I would start by searching the marketplace for the data source I need: public LinkedIn company data, job listings, public posts, Amazon or Walmart product data, e-commerce reviews, company datasets, or real estate data.
At this stage, I am not buying anything yet. I am checking whether the dataset exists and whether it looks close to my use case.
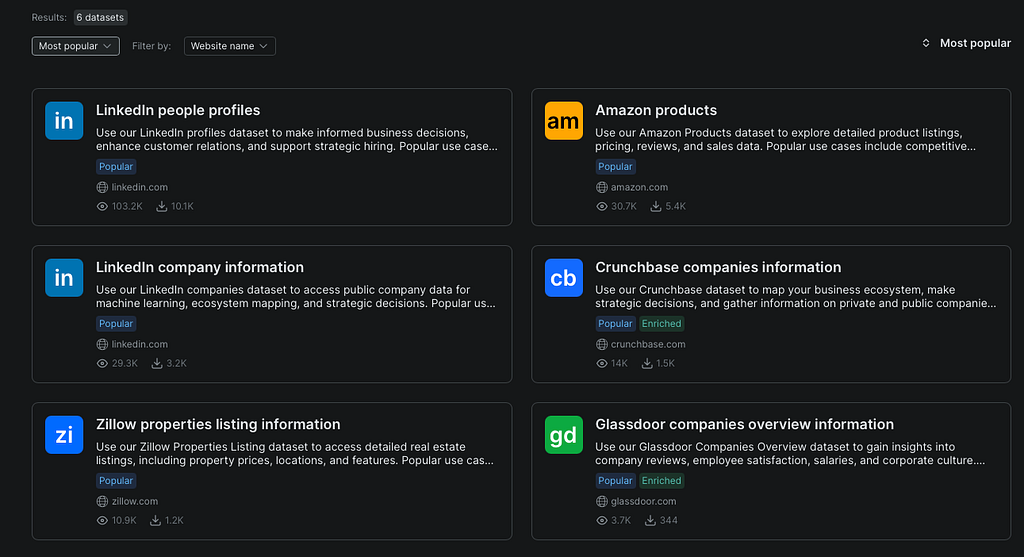
Step 2: Inspect the schema
This is the most important step. Before thinking about record count, I want to understand the fields. A huge dataset is useless if it does not contain the columns I need, so I would check field names, data types, required and optional fields, timestamps, source URLs, IDs, nested structures, locations, and product or company identifiers.
The dataset metadata API endpoint returns available fields, data types, and descriptions.
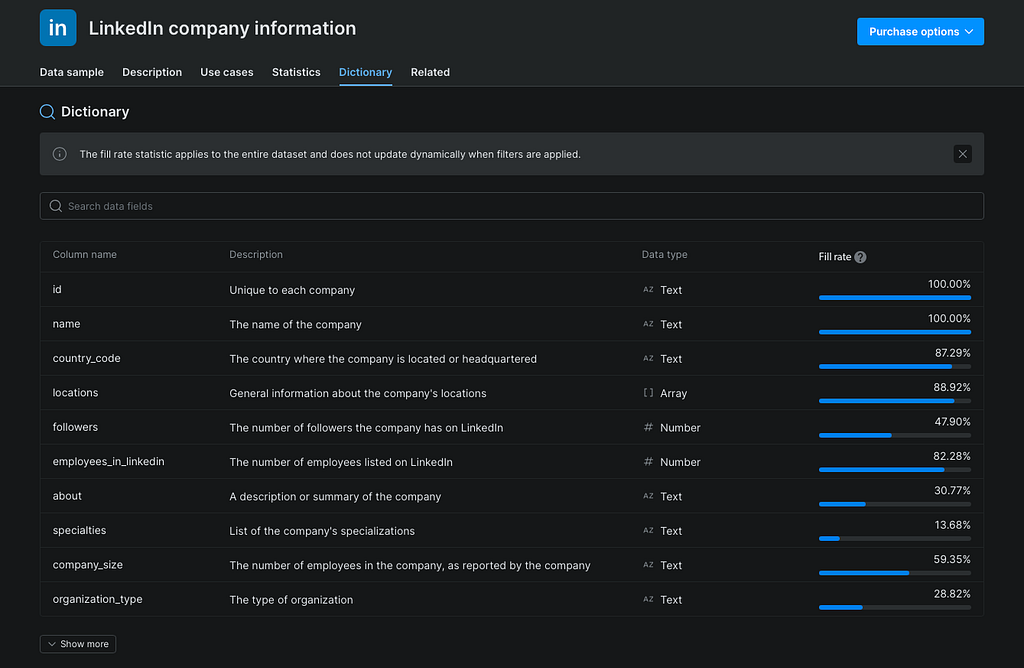
Before using any dataset, I want to see the actual fields, data types, descriptions, and fill rates.
This is where you prevent future problems. Bad data decisions usually start with skipping schema inspection.
Step 3: Download a sample
I would never design a real pipeline around a dataset without looking at a sample first. A sample helps me check whether fields are populated, null values are acceptable, locations are normalized, categories are useful, URLs are valid, duplicates are manageable, and the structure is easy to load into pandas, Spark, DuckDB, Snowflake, or BigQuery.
Bright Data has a free dataset samples page that mentions sample downloads in JSON and CSV formats.

Step 4: Filter the dataset
Most teams do not need "everything." They need a focused subset: companies in a specific country, jobs with certain titles, products in one category, recently updated records, items above a rating threshold, sellers from a specific marketplace, or companies in a certain industry.
Fields and filters can be customized through the UI or API to narrow the dataset to the exact subset needed.
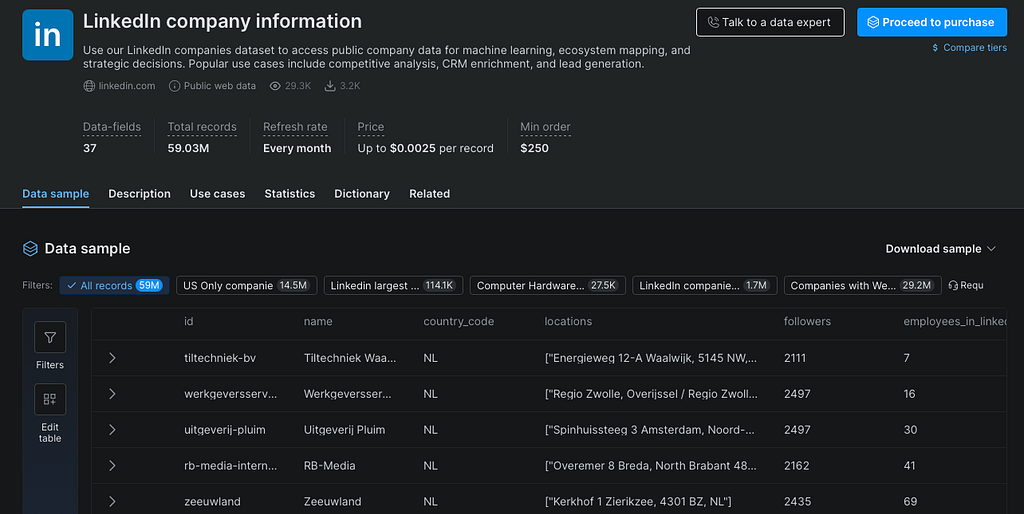
This is another big difference from DIY scraping: with your own scraper, filtering often happens after collection; with a marketplace dataset, you can often filter before ingestion. That can save storage, processing time, and money.
Step 5: Choose the delivery format
CSV works for local analysis, JSON or NDJSON for backend pipelines, Parquet for analytics and ML workflows, and cloud delivery for production data platforms. For larger analytics datasets, my default would be Parquet: compact, columnar, and compatible with modern data tools.
The data engineering comparison
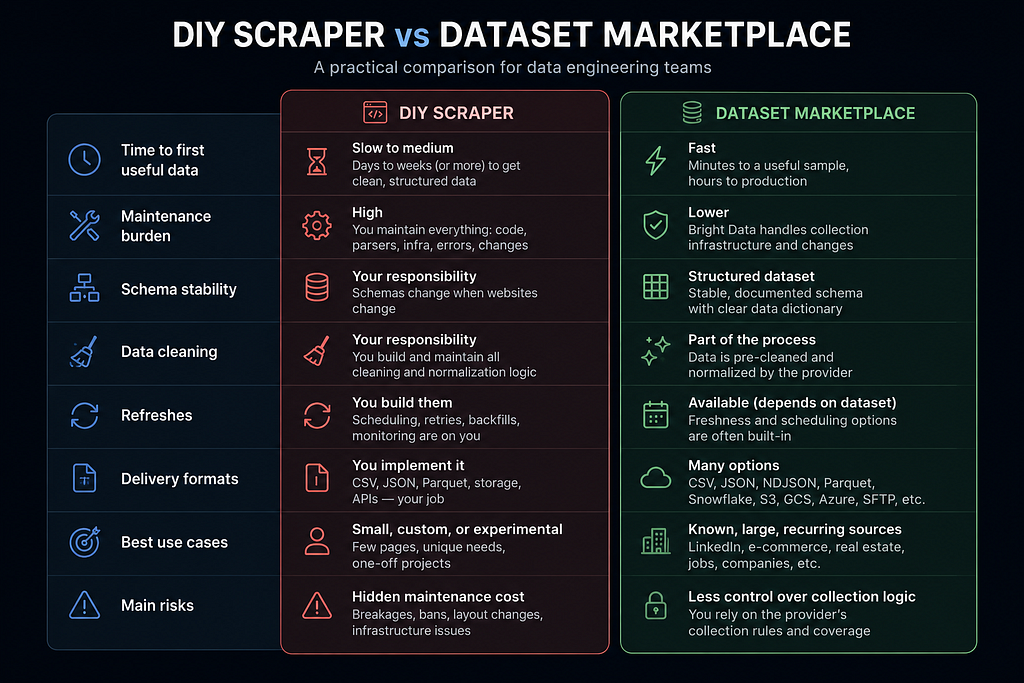
Here is the simplest way I think about it. Building your own scraper gives you maximum control: you decide what to collect, how to parse it, how often to refresh it, and what the final dataset should look like.
But that control comes with responsibility. You own the extraction logic, proxies, retries, failures, cleaning, schema stability, refreshes, delivery formats, and every future fix when something breaks.
That is fine for small, custom, or experimental tasks. If I need a few hundred records from a simple public website, I will probably write the scraper myself. But once the project becomes larger, the trade-off changes. If I need structured LinkedIn-style or e-commerce data, and I care about quality, freshness, and delivery formats, I do not want to spend most of my time maintaining scraping infrastructure.
Dataset Marketplace trades low-level collection control for a faster path to usable data.
When I would still build my own scraper
I do not think engineers should stop building scrapers completely. There are still good reasons to build your own: the website is simple and stable, the dataset is small, the use case is highly custom, the source is internal, you need real-time interaction, or you need fields that are not available in any existing dataset.
For millions of structured records from LinkedIn or e-commerce sources, with refreshes and stable delivery formats, it is worth checking whether the dataset already exists before writing code.
Where Dataset Marketplace fits best
In my opinion, Bright Data's Dataset Marketplace is most useful for teams working on market research, competitive intelligence, e-commerce analytics, pricing intelligence, lead enrichment, job market analysis, ML and RAG pipelines, or AI agents that need structured public web data.
These are cases where data quality matters more than scraping pride. The goal is to build a useful system, not to prove you can collect data manually.
A realistic example: RAG over company data
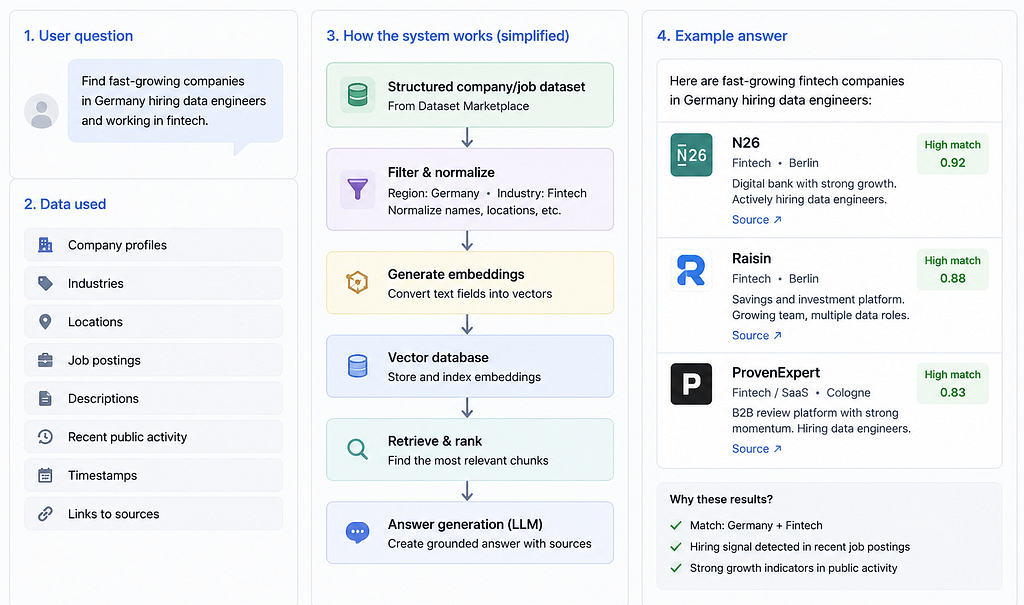
Imagine you want to build an internal research assistant. A user asks:
"Find fast-growing companies in Germany hiring data engineers and working in fintech."
To answer this well, your system may need company profiles, industries, locations, job postings, descriptions, recent public activity, timestamps, and source links. You could build scrapers for all of these, but then you are maintaining data collection instead of improving the assistant.
A better workflow may be:
- Start with a structured company/job dataset.
- Filter it by region and industry.
- Normalize company names and locations.
- Generate embeddings.
- Store the data in a vector database.
- Build retrieval and ranking logic.
- Evaluate answer quality.
That is the difference. The marketplace removes a large part of the low-level collection burden so you can focus on higher-value work.
My honest take
After working with data pipelines for a while, I have become less impressed by clever scrapers and more impressed by reliable data flows. A scraper that works once is not enough. A structured, documented, refreshable dataset that is easy to deliver into your stack is often much more useful.
That is why Bright Data's Dataset Marketplace makes sense to me. It is not magic: you still need to inspect the schema, validate the sample, understand your use case, and check freshness, coverage, and data quality. But it changes the starting point.
Conclusion: stop doing expensive work by default
The real mistake is building a scraper by default, before checking whether a ready-made dataset already fits the use case.
For LinkedIn data, e-commerce data, market research, ML pipelines, and RAG systems, the first question should be:
"Does this dataset already exist?"
If it does, and if the schema, freshness, and coverage match your needs, a marketplace dataset may be the faster and more reliable option.
Build scrapers when you need custom collection. Use ready-made datasets when the data already exists and your real goal is analysis, intelligence, or product development.
Users do not care how sophisticated your scraper is. They care whether your system gives them useful answers. Sometimes the best engineering decision is to stop scraping and start building.
Bright Data's Dataset Marketplace covers 250+ domains, with datasets available in JSON, CSV, Parquet, and other formats. If your team is spending engineering time collecting data that already exists, explore the marketplace or download a free sample to test against your use case.