
Der erste GKE-Cluster, den du hochziehst, fühlt sich beruhigend managed an: Google betreibt die Control Plane, Nodes reparieren sich selbst, Upgrades sind ein Klick. Man nimmt leicht an, „managed“ hieße „sicher“. Tut es nicht. Ein Standard-Cluster ist gebaut, um zu funktionieren, und fast jede wichtige Sicherheitskontrolle ist opt-in — der öffentliche Endpunkt, die breiten Node-Berechtigungen, die fehlende Image-Provenance, die Root-Container. Nichts davon ist ein Bug. Es ist einfach nicht das Problem deines Bedrohungsmodells, bis es das ist.
Dies ist eine Secure-by-Default-Referenzarchitektur für GKE: ein Bauplan, in dem die gehärtete Konfiguration die Grundlinie ist, kein Backlog-Item. Sie ist als Defense in Depth organisiert — sechs unabhängige Schichten, von denen jede annimmt, dass die davor versagen könnte.

Das Ziel ist keine einzelne Mauer. Es ist, dass ein Angreifer, der an der Identität vorbeikommt, immer noch auf die Netzwerkkontrollen trifft, wer am Netzwerk vorbeikommt, immer noch auf ein Supply-Chain-Gate, und so weiter. Bricht eine Schicht, halten die anderen.
Das ist die Sicherheitshälfte einer größeren GCP-Architekturgeschichte. Für die Messaging-Seite — ein event-getriebenes System sauber statt sicher zu halten — siehe Pub/Sub oder Eventarc? Event-Driven GCP ohne Spaghetti.

Gehen wir die Schichten durch, von außen nach innen.
Schicht 1 — Identität: die statischen Schlüssel abschaffen
Die wirkungsvollste Änderung an einem GKE-Cluster hat nichts mit dem Netzwerk zu tun. Es ist, langlebige Service-Account-Schlüssel loszuwerden.
Das alte Muster ist eine JSON-Schlüsseldatei, in den Pod gemountet. Es funktioniert, und es ist eine Haftung: Diese Datei wird in Images kopiert, in Git committet, in einem Env-Dump ausgegeben, und sie gewährt weiter Zugriff, bis ein Mensch es bemerkt und rotiert. Ein geleakter statischer Schlüssel ist die häufigste — und am besten vermeidbare — Cloud-Kompromittierung.
Workload Identity Federation ersetzt es. Ein Kubernetes-Service-Account wird an eine Google-Identität gebunden; wenn der Pod eine GCP-API aufruft, prägt Google an Ort und Stelle ein kurzlebiges, IAM-begrenztes Token. Es gibt keinen Schlüssel im Ruhezustand, nichts zum Leaken, und das Token läuft von selbst ab.
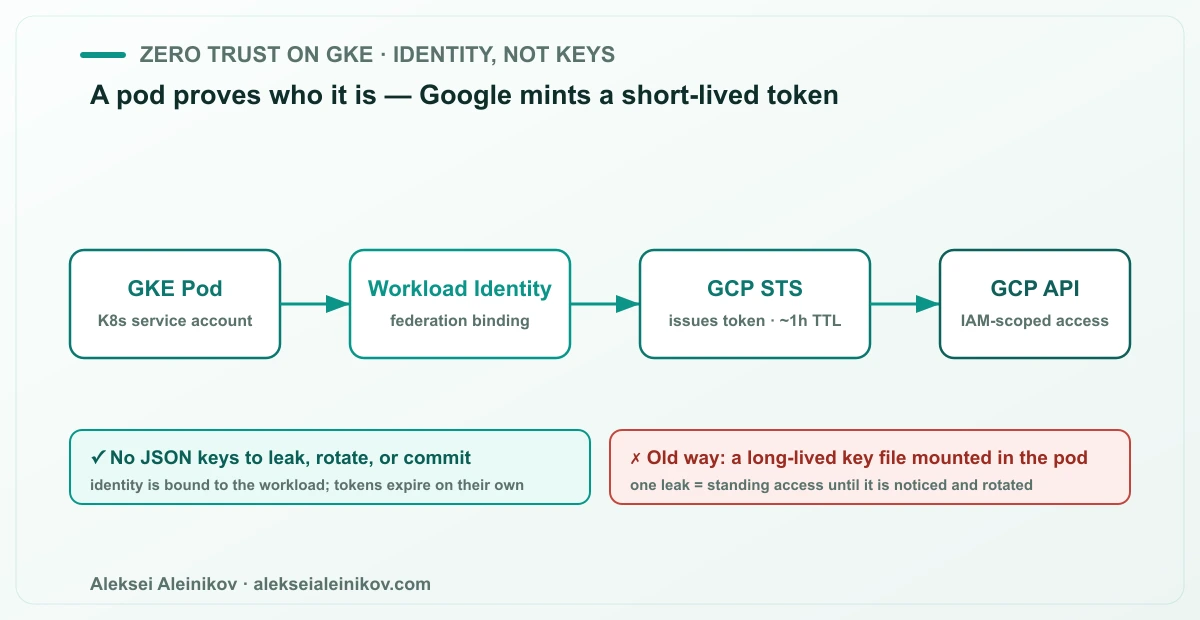
# Workload Identity am Cluster aktivierengcloud container clusters update CLUSTER \ --workload-pool=PROJECT_ID.svc.id.goog
# einen Kubernetes-SA an einen Google-SA bindengcloud iam service-accounts add-iam-policy-binding \ GSA@PROJECT_ID.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:PROJECT_ID.svc.id.goog[NAMESPACE/KSA]"Die Regel für diese Schicht: keine Service-Account-JSON-Schlüssel irgendwo im Cluster. Braucht ein Workload GCP-Zugriff, föderiert er. Braucht ein Mensch Zugriff, nutzt auch er kurzlebige Credentials.
Schicht 2 — Netzwerk: privat by default
Die nächste Annahme, die es umzukehren gilt, ist Erreichbarkeit. Ein Standard-Cluster kann seine Control Plane dem öffentlichen Internet aussetzen und Nodes auf routbare Adressen legen. Beides sollte in Produktion nicht gelten.
- Privater Cluster — Nodes erhalten nur interne IPs; der Control-Plane-Endpunkt ist privat.
- Autorisierte Netze — der API-Server ist nur aus den CIDR-Bereichen erreichbar, die du benennst (dein CI, dein Bastion, dein VPN).
- Cloud Armor — eine WAF- und DDoS-Schicht vor allem, was du über einen Load Balancer exponierst, mit auf deinen Traffic abgestimmten Regeln statt der Defaults.
Das Prinzip: Nichts ist erreichbar, außer es gibt einen Grund dafür. Das Netzwerk ist nicht die ganze Verteidigung — es ist die Schicht, die dir Zeit verschafft, wenn die Identität umgangen wird.
Schicht 3 — Supply Chain: nur signierte Images laufen
Der meiste „Container-Security“-Aufwand fließt in das Scannen von Images. Scannen sagt dir, was in einem Image steckt; es garantiert nicht, dass nur deine Images laufen. Diese Garantie ist die Supply-Chain-Schicht, und auf GKE ist sie Binary Authorization.
Binary Authorization ist ein Admission-Gate. Jedes Image muss die von deiner Policy geforderten Attestierungen tragen — typischerweise eine Signatur deines CI, die belegt, dass es aus geprüftem Quellcode gebaut wurde und seine Gates bestanden hat. Alles Unsignierte oder nicht Vertrauenswürdige wird blockiert, bevor es einen Node erreicht.
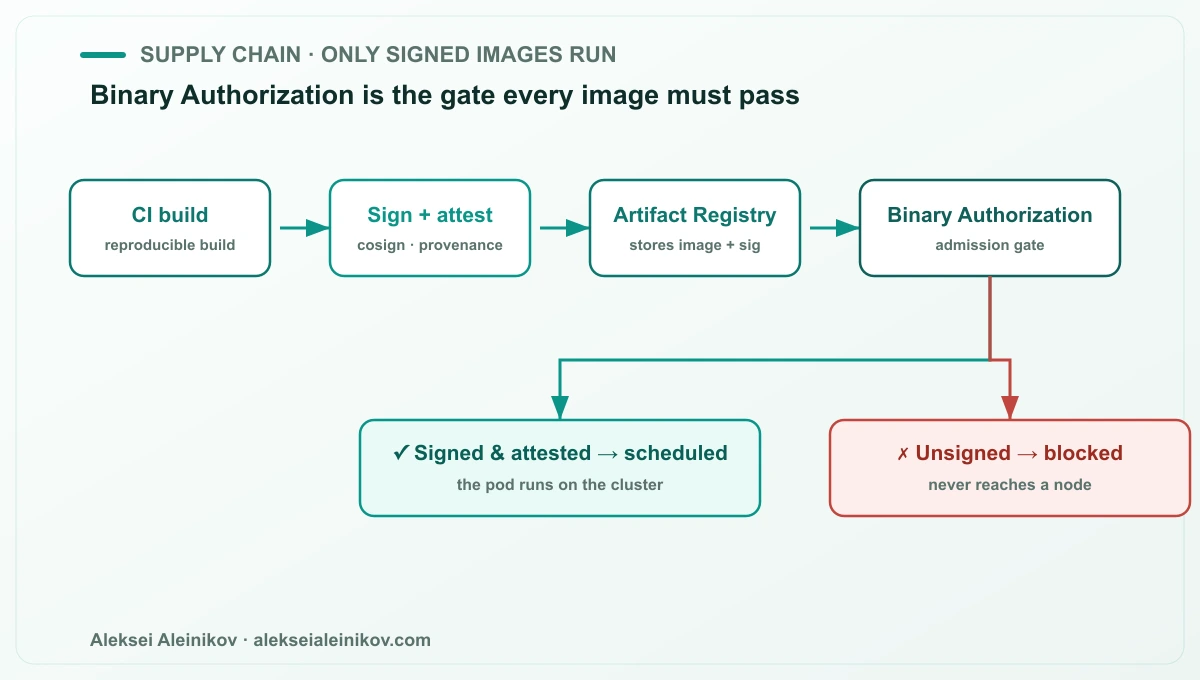
# Binary-Authorization-Policy (Auszug)globalPolicyEvaluationMode: ENABLEdefaultAdmissionRule: evaluationMode: REQUIRE_ATTESTATION enforcementMode: ENFORCED_BLOCK_AND_AUDIT_LOG requireAttestationsBy: - projects/PROJECT_ID/attestors/prod-attestorDas schließt die Lücke zwischen „wir bauen sicher“ und „nur was wir sicher gebaut haben, läuft auch“ — genau der Raum, in dem Supply-Chain-Angriffe leben. Rolle es zuerst im Audit-Modus aus, um zu sehen, was blockiert würde, und schalte dann auf Enforcement.
Schicht 4 — Admission und Policy: Deny by Default
Binary Authorization beantwortet „ist dieses Image vertrauenswürdig?“. Es beantwortet nicht „gehorcht dieser Workload unseren Regeln?”. Das ist die Aufgabe einer Policy-Engine — OPA Gatekeeper oder Kyverno — die als Admission-Controller läuft.
Hier kodierst du die für deine Plattform spezifischen Regeln, als Code, Deny-by-Default erzwungen:
- nur Images aus deiner Artifact Registry
- erforderliche Labels und Owner an jedem Workload
- Ressourcen-Requests und -Limits verpflichtend
- kein
hostPath, keine privilegierten Container, keinelatest-Tags
# Kyverno: privilegierte Container clusterweit blockierenapiVersion: kyverno.io/v1kind: ClusterPolicymetadata: name: disallow-privilegedspec: validationFailureAction: Enforce rules: - name: privileged-containers match: any: - resources: kinds: ["Pod"] validate: message: "Privilegierte Container sind nicht erlaubt." pattern: spec: containers: - =(securityContext): =(privileged): "false"Kombiniere das mit Kubernetes Pod Security als eingebautem Boden. Pod Security erzwingt die Grundlinie; die Policy-Engine erzwingt alles, was deine Organisation speziell interessiert.
Schicht 5 — Workload-Runtime: den Blast-Radius verkleinern
Nimm an, dass irgendwann jemand eine Shell in einem Container bekommt. Schicht 5 dreht sich darum, das so langweilig wie möglich zu machen.
- Als non-root laufen — ein
runAsNonRoot-Security-Context, keinrootim Image. - Read-only Root-Dateisystem — schreibbare Pfade sind explizite
emptyDir-Mounts, sonst nichts. - Capabilities droppen — von keinen starten und nur zurückgeben, was nötig ist.
- seccomp — das
RuntimeDefault-Profil filtert gefährliche Syscalls.
securityContext: runAsNonRoot: true runAsUser: 10001 readOnlyRootFilesystem: true allowPrivilegeEscalation: false capabilities: drop: ["ALL"] seccompProfile: type: RuntimeDefaultKeine dieser Maßnahmen stoppt einen Einbruch allein. Zusammen bedeuten sie, dass ein kompromittierter Container ein verschlossener Raum ist, kein Flur.
Schicht 6 — Observability: nimm an, du brauchst das Band
Die letzte Schicht ist keine Prävention, sondern Wissen. Wenn etwas schiefgeht, ist der Unterschied zwischen einer Fünf-Minuten-Triage und einem Fünf-Tage-Incident, ob du es sehen kannst.
- Audit-Logs — Kubernetes- und Cloud-Audit-Logs, aufbewahrt und abfragbar.
- Runtime-Detection — ein Tool wie Falco oder GKEs eingebaute Threat Detection, das auf anomale Syscalls und Prozessaktivität achtet.
- SLO-basiertes Alerting — Alerts, die auf Symptome feuern, die deine Nutzer spüren, mit klarer Zuständigkeit, statt einer Wand aus Rauschen, die niemand liest.
Security-Observability ist, was die ersten fünf Schichten von „wir hoffen, es hat geklappt“ zu „wir können beweisen, was passiert ist“ macht.
Wie man es ohne Big Bang einführt
Du rollst das nicht auf einmal aus. Ordne die Arbeit danach, wie viel stehendes Risiko jede Schicht entfernt:
- Identität zuerst. Migriere von statischen Schlüsseln zu Workload Identity Federation — höchste Wirkung, und ein geleakter Schlüssel ist die günstigstmögliche Kompromittierung.
- Netzwerk als Zweites. Private Control Plane, autorisierte Netze.
- Supply Chain und Policy als Drittes, beide im Audit-Modus vor dem Enforcement, damit du siehst, was brechen würde.
- Runtime-Härtung, während du jeden Workload anfasst.
- Observability durchgehend verdrahtet, damit du jede Schicht beim Aktivieren beobachten kannst.
Erzwinge nichts in Produktion, bevor du es im Audit-Modus beobachtet hast. Secure-by-Default ist ein Ziel, das du bewusst erreichst — aber bist du dort, ist die sichere Konfiguration die, die du gratis bekommst, und jeder neue Cluster startet gehärtet, statt zu hoffen, dass jemand daran denkt, es später zu tun.
Fazit
„Managed“ ist nicht „sicher“, und ein Standard-GKE-Cluster beweist das jeden Tag. Die Lösung ist keine einzelne Kontrolle, sondern ein Stapel unabhängiger: statische Schlüssel mit Workload Identity Federation abschaffen, das Netzwerk privat machen, nur signierte Images mit Binary Authorization zulassen, Deny-by-Default-Policy mit einer Policy-Engine erzwingen, die Runtime härten und all das mit echter Observability beobachten. Führe sie in Risiko-Reihenfolge ein, betreibe alles im Audit vor dem Enforcement, und Secure-by-Default hört auf, ein Slogan zu sein, und wird zur Grundlinie, die jeder Workload erbt.
