Wenn du je danach gesucht hast, wie man Daten aus dem Web sammelt, hast du die beiden Begriffe gesehen, als wären sie dasselbe: Web Scraping und Web Crawling. Sind sie nicht. Sie zu verwechseln ist der häufigste Grund, warum Datenprojekte mit dem falschen Werkzeug starten.
Hier die kurze Version — und dann die praktische.
- Ein Crawler entdeckt und folgt Links. Er beantwortet „welche Seiten existieren und wohin gehe ich als Nächstes?“
- Ein Scraper extrahiert Daten aus einer Seite. Er beantwortet „welche Informationen nehme ich von dieser Seite mit?“
Sie sind keine Konkurrenten. In fast jedem echten Projekt sind sie zwei Stufen derselben Pipeline: crawlen, um die Seiten zu finden, scrapen, um die Daten zu ziehen.

Die 30-Sekunden-Antwort
| Web Crawling | Web Scraping | |
|---|---|---|
| Aufgabe | URLs entdecken und verfolgen | Daten aus einer Seite extrahieren |
| Beantwortete Frage | Wohin gehen? | Was mitnehmen? |
| Ergebnis | Eine Liste von Links / eine Sitemap | Strukturierte Daten (Preise, Bewertungen, Titel) |
| Klassisches Beispiel | Googlebot kartiert das Web | Alle Produktpreise einer Kategorie ziehen |
| Reichweite | Breit — viele Seiten | Tief — Felder auf einer Seite |
Wenn du dir einen Satz merkst: Crawling ist Navigation, Scraping ist Extraktion. Eine Suchmaschine ist überwiegend ein Crawler. Ein Preismonitor ist überwiegend ein Scraper. Ein „sammle jedes Produkt in diesem Shop“-Job ist beides.
Wie Web Crawling funktioniert
Ein Crawler startet von einer oder mehreren Seed-URLs und breitet sich nach außen aus:
- Die Seed-Seite abrufen.
- Sie parsen und jeden Link extrahieren.
- Neue Links in eine Warteschlange legen (die URL-Frontier).
- Wiederholen — jede eingereihte URL besuchen,
robots.txtrespektieren und bereits gesehene Seiten deduplizieren.
Ein minimaler Crawler in Python sieht so aus:
import requestsfrom urllib.parse import urljoin, urlparsefrom bs4 import BeautifulSoup
def crawl(seed, max_pages=50): seen, queue, base = set(), [seed], urlparse(seed).netloc
while queue and len(seen) < max_pages: url = queue.pop(0) if url in seen: continue seen.add(url)
try: html = requests.get(url, timeout=10).text except requests.RequestException: continue
soup = BeautifulSoup(html, "html.parser") for a in soup.select("a[href]"): link = urljoin(url, a["href"]) # auf derselben Website bleiben, Besuchtes überspringen if urlparse(link).netloc == base and link not in seen: queue.append(link)
return seen
urls = crawl("https://example.com")print(f"{len(urls)} URLs entdeckt")Das ist die ganze Idee des Crawlings: breitensuche-basierte Link-Entdeckung. Das Ergebnis ist eine Menge von URLs — noch keine Daten.
Wie Web Scraping funktioniert
Ein Scraper nimmt eine einzelne Seite und zieht genau die Felder heraus, die dich interessieren. Wie du die URL gefunden hast, ist ihm egal — das war die Aufgabe des Crawlers.
import requestsfrom bs4 import BeautifulSoup
def scrape_product(url): html = requests.get(url, timeout=10).text soup = BeautifulSoup(html, "html.parser")
return { "title": soup.select_one("h1").get_text(strip=True), "price": soup.select_one(".price").get_text(strip=True), "rating": soup.select_one(".rating").get_text(strip=True), }
data = scrape_product("https://example.com/product/123")print(data) # {"title": "...", "price": "...", "rating": "..."}Crawling gab uns das Wo. Scraping gibt uns das Was. Verkette beide, und du hast eine Pipeline.
Crawling + Scraping: Eine echte Pipeline
So passen sie in der Praxis zusammen — sagen wir, du willst jedes Produkt eines Shops:
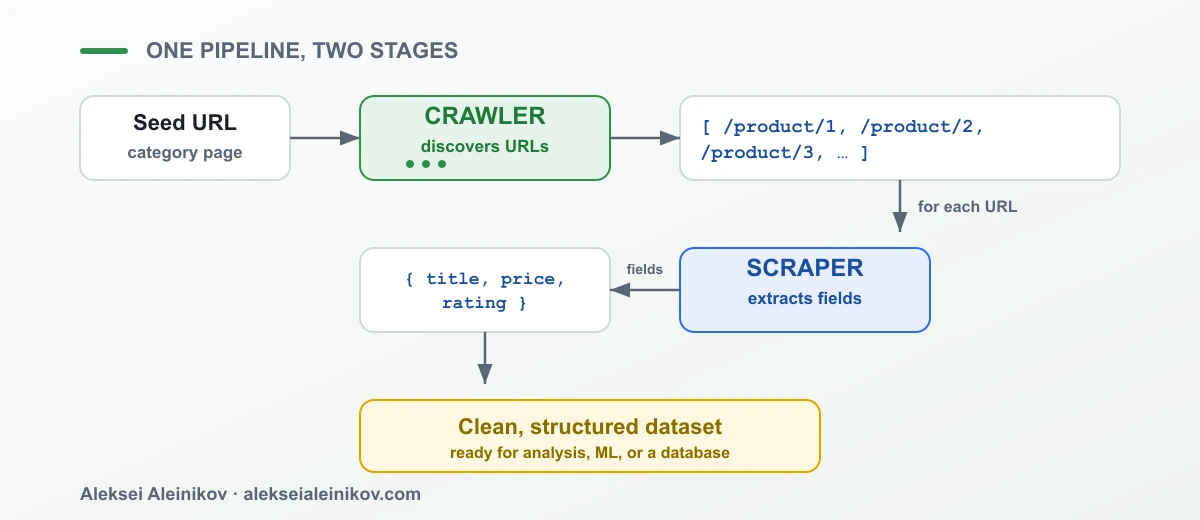
Der Crawler zählt die URLs auf; der Scraper macht aus jeder eine Datenzeile. Auf dem Papier einfach — und dann lässt du es gegen eine echte Website laufen, und es bricht.
Warum beide in Produktion brechen
Der Code oben funktioniert auf example.com. Auf einem echten, kommerziellen Ziel nicht, denn im großen Maßstab siehst du überhaupt nicht wie ein menschlicher Besucher aus:
- Du sendest hunderte oder tausende Anfragen aus einem schmalen Satz von IPs.
- Viele Seiten rendern ihre Inhalte per JavaScript, sodass
requestsnur eine leere Hülle bekommt. - Websites bekämpfen Bots mit Rate-Limits, CAPTCHAs und Browser-Fingerprinting.
- Geo-eingeschränkte Inhalte ändern sich je nachdem, woher die Anfrage kommt.
Das ist die Wand, gegen die jedes Scraping- und Crawling-Projekt läuft. Sie selbst zu lösen bedeutet, Proxy-Rotation, Headless-Browser, CAPTCHA-Handling und Retry-Logik zu bauen und zu warten — ein ganzes Subsystem, das mit deinem eigentlichen Datenziel nichts zu tun hat.
Genau diese Schicht ist Bright Data gebaut zu ersetzen.
Den Crawl und einfache Scrapes entsperren
Für den häufigen Fall — eine URL senden, sauberes, gerendertes HTML zurückbekommen — übernimmt die Bright Data Web Unlocker API Proxy-Rotation, Anti-Bot-Umgehung, CAPTCHA-Lösung und JavaScript-Rendering hinter einer einzigen Anfrage. Dein Crawler und Scraper kümmern sich nicht mehr um Blocks:
import requests
API_URL = "https://api.brightdata.com/request"HEADERS = {"Authorization": "Bearer YOUR_API_TOKEN"}
def fetch(url): payload = {"zone": "web_unlocker", "url": url, "format": "raw"} resp = requests.post(API_URL, json=payload, headers=HEADERS, timeout=60) return resp.text # vollständig gerendertes, entsperrtes HTML
html = fetch("https://example.com/product/123")# direkt an BeautifulSoup wie zuvor übergebenDie Komplexität wandert aus deinem Code in die Zugriffsschicht — genau dorthin, wo sie hingehört. Die Web Unlocker API macht aus „eine URL rein, gerendertes HTML raus“ etwas, das einfach funktioniert, im großen Maßstab.
Seiten scrapen, die einen echten Browser brauchen
Manche Ziele brauchen mehr als eine gerenderte Seite — Klicks, Logins, Scrollen, mehrstufige Navigation. Dafür ist ein vollwertiger Browser das richtige Werkzeug. Die Bright Data Scraping Browser API gibt dir ein verwaltetes, entferntes Chrome, an das sich Playwright oder Puppeteer über CDP anhängen, mit eingebauten Proxys und Unblocking — so bekommst du Browser-Grade-Scraping, ohne selbst eine Flotte von Headless-Browsern zu betreiben:
from playwright.sync_api import sync_playwright
CDP_URL = "wss://YOUR_ENDPOINT@brd.superproxy.io:9222"
with sync_playwright() as p: browser = p.chromium.connect_over_cdp(CDP_URL) page = browser.new_page() page.goto("https://example.com/product/123") page.wait_for_selector(".price") print(page.inner_text(".price")) browser.close()Die Faustregel: Greif zur Scraping Browser API, wenn der Workflow Interaktion braucht (Klicks, Formulare, Infinite Scroll), und zur Web Unlocker API, wenn du nur das gerenderte HTML einer URL brauchst.
Ist Web Scraping legal?
Das ist die Frage, die alle stellen — also seien wir klar und ehrlich.
Öffentlich verfügbare Daten zu scrapen ist in vielen Rechtsordnungen weitgehend zulässig, und Gerichte — allen voran die hiQ v. LinkedIn-Reihe in den USA — haben den Zugriff auf öffentliche Daten wiederholt vom unbefugten Zugriff auf geschützte Systeme unterschieden. Aber „öffentliche Daten sind generell okay“ ist kein Freibrief. Die Rechtslage hängt davon ab, was du sammelst und wie:
- Nutzungsbedingungen respektieren, wo sie für deinen Zugriff gelten.
- Keine personenbezogenen Daten ohne rechtliche Grundlage verarbeiten (DSGVO/CCPA zählen).
- Keine Authentifizierung umgehen — Scraping hinter einem Login ist eine andere rechtliche Kategorie.
- Keine urheberrechtlich geschützten Inhalte zur Weiterveröffentlichung scrapen.
- Anfrageraten vernünftig halten, damit du den Zieldienst nicht beeinträchtigst.
Crawling hat dieselben Grenzen. robots.txt ist eine zu respektierende Norm, kein Gesetz — aber sie zu ignorieren und dabei eine Website zu überfluten ist genau der Weg, auf die falsche Seite von Ethik und Rechtsstreit zu geraten. Für alles Kommerzielle: Beratung für den konkreten Anwendungsfall einholen.
Beste Tools für jede Aufgabe (2026)
| Bedarf | Greif zu |
|---|---|
| Eine Website crawlen, um URLs zu entdecken | Scrapy oder ein eigener BFS-Crawler |
| Felder aus statischem HTML extrahieren | BeautifulSoup, lxml, Cheerio |
| Aus JS-lastigen Seiten extrahieren | Playwright / Puppeteer |
| Entsperrtes HTML von jeder URL holen | Bright Data Web Unlocker API |
| Browser-Grade-Scraping im Maßstab | Bright Data Scraping Browser API |
Die Open-Source-Tools geben dir die Logik; die Zugriffsschicht gibt dir die Zuverlässigkeit. In Produktion willst du fast immer beides.
Das Fazit
Web Crawling und Web Scraping sind nicht dasselbe, und sie sind keine Rivalen:
- Crawling entdeckt, wo die Daten sind.
- Scraping extrahiert, was die Daten sind.
- Zusammen bilden sie eine Pipeline: die URLs finden, dann die Daten ziehen.
Die Logik ist einfach. Der schwere Teil — der, der ein Wochenend-Skript von einem Produktionssystem trennt — ist, im großen Maßstab entsperrt zu bleiben. Erledige die Entdeckung mit einem Crawler, die Extraktion mit einem Scraper und die Block-Wand mit einer Unblocking-Schicht wie der Web Unlocker API oder der Scraping Browser API — und das Ganze fühlt sich nicht mehr wie Magie an, sondern wie Installation, die du tatsächlich kontrollierst.