
Schnelle Queries, skalierbare Pipelines und Daten, denen man vertraut.
Datensysteme versagen leise: Eine Query, die bei tausend Zeilen schnell war, kriecht bei einer Million; eine Pipeline, die im Demo lief, verliert unter Last Datensätze. Datensysteme schnell und korrekt zu halten, während das Volumen wächst, ist eine eigene Disziplin — eine, die ich über Produktiv-Pipelines und Analytics-Workloads praktiziere.
Artikel in diesem Hub
6 Artikel
Playwright Web Scraping auf Kubernetes produktionsreif betreiben mit Bright Data (2026)
Das Schwierige ist nicht das Schreiben des Scrapers, sondern ihn zuverlässig in der Produktion zu betreiben. Eine praktische Anleitung mit Playwright, Bright Data Browser API und Kubernetes Jobs.
Artikel lesen →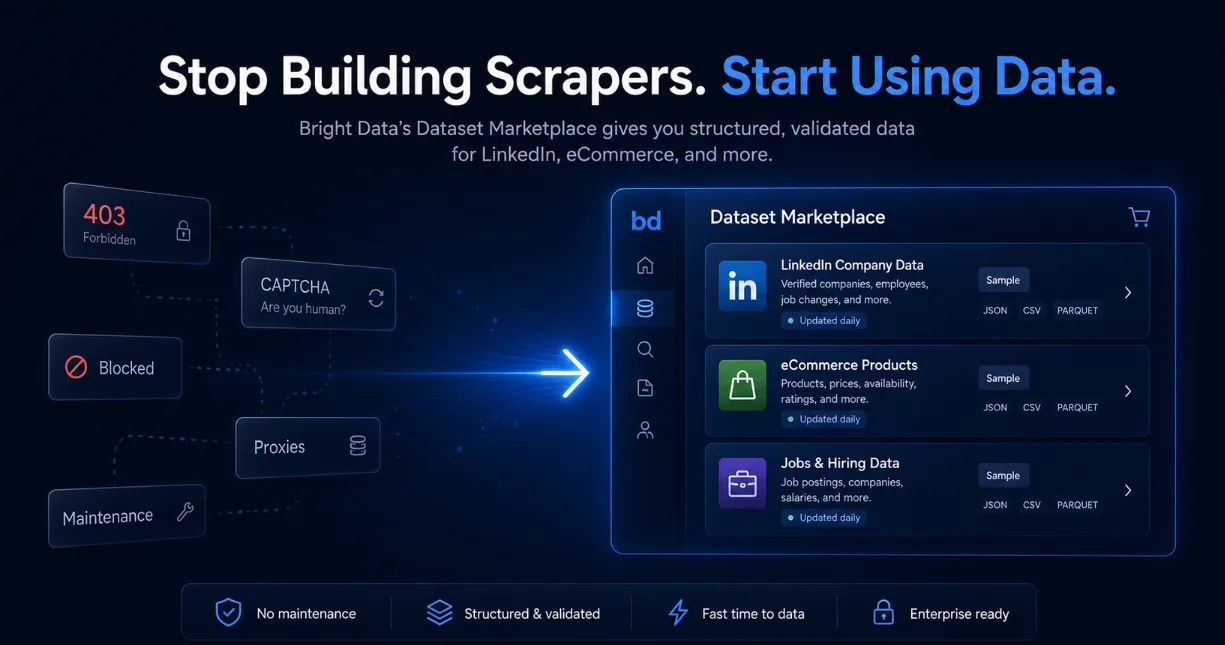
LinkedIn-Scraping vs. Datensatz kaufen 2026: 3 Tage Code, die ich hätte sparen können
Eine praxisnahe Bewertung von Bright Data's Dataset Marketplace – und warum fertige LinkedIn- und E-Commerce-Datensätze wochenlange Scraping-Arbeit einsparen können
Artikel lesen →
Echtzeit-RAG in Python: Live-Google-Ergebnisse für dein LLM (2026)
Was wäre, wenn deine RAG-Pipeline kurz vor der Antwortgenerierung frischen Web-Kontext abrufen könnte? Eine praktische Anleitung zum Aufbau einer Live-Such-Retrieval-Schicht mit Bright Data SERP API und Python.
Artikel lesen →
Kafka vs Pub/Sub 2026: Wenn Managed Messaging einen Fintech Launch rettet
Eine 2026 Fintech Messaging Case Study: Wie Kafka Backlog, Broker Disk Pressure und ein Rebalance Storm Checkout brachen, und warum Google Cloud Pub/Sub den Payment Flow aus der Gefahrenzone holte.
Artikel lesen →
Python Web Scraping ohne Proxy-Verwaltung: Bright Data Web Unlocker API (2026)
Das Schwierige ist nicht das Parsen von HTML. Es ist das Erhalten einer nutzbaren Antwort von modernen geschützten Websites. Eine Schritt-für-Schritt-Anleitung mit Bright Data Web Unlocker API, Python und BeautifulSoup.
Artikel lesen →
SQL Query Optimization 2026: 7 einfache Techniken fuer schnellere Datenbank-Performance
Sieben praktische SQL-Query-Optimierungstechniken fuer schnellere Datenbank-Performance, mit PostgreSQL-Beispielen fuer JOINs, IN-Listen, EXISTS, Datumsbereiche, Aggregationen und Deduplizierung.
Artikel lesen →
Häufige Fragen
Welchen Data-Engineering-Hintergrund haben Sie?
Sind Sie verfügbar für eine Zusammenarbeit?
Wie starten wir eine Zusammenarbeit?
Hält Ihre Datenschicht mit?
Von langsamen Queries über fragile Pipelines bis zur groß angelegten Sammlung helfe ich Teams, Datensysteme zu bauen, die schnell und korrekt bleiben.
Data-Engineering-Leistungen ansehen →