
Fast queries, scalable pipelines and data you can trust.
Data systems fail quietly: a query fast at a thousand rows crawls at a million, a pipeline that worked in a demo drops records under load. Keeping data systems fast and correct as volume grows is its own discipline — one I practise across production pipelines and analytics workloads.
Articles in this hub
6 articles
Production-Grade Playwright Web Scraping on Kubernetes with Bright Data (2026)
The hard part is not writing the scraper. It is making it run reliably in production. A step-by-step guide using Playwright, Bright Data Browser API, and Kubernetes Jobs and CronJobs.
Read article →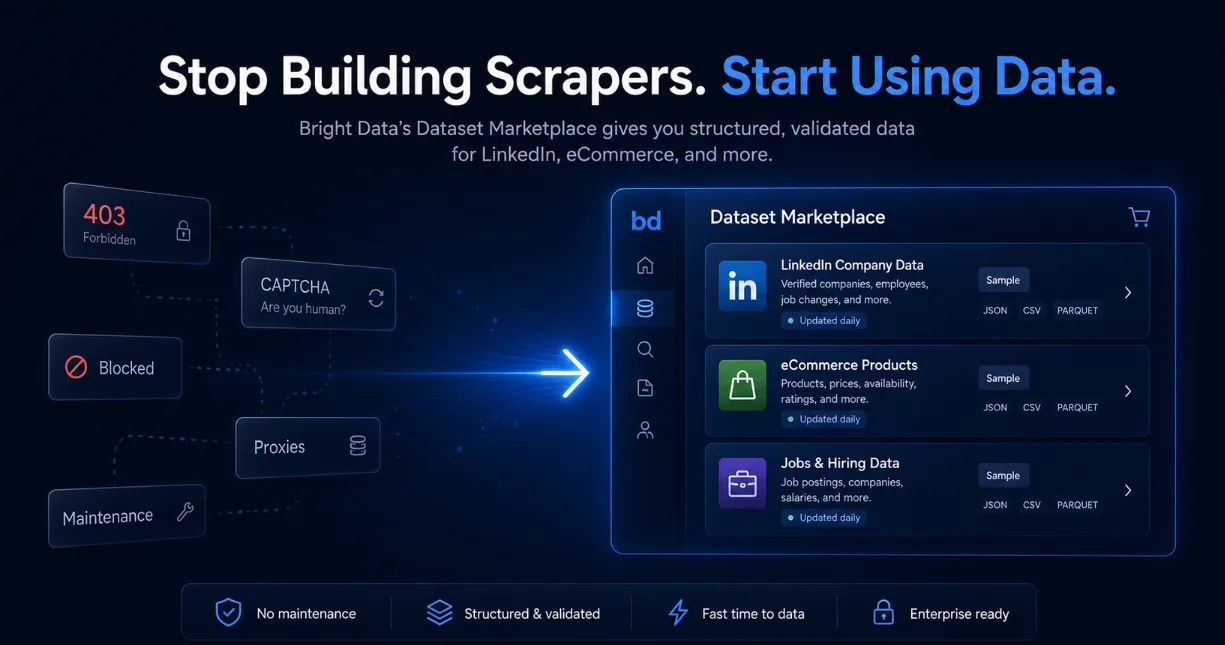
LinkedIn Scraping vs. Buying a Dataset in 2026: 3 Days of Code I Could Have Skipped
A data engineer's review of Bright Data's Dataset Marketplace: why ready-made LinkedIn and e-commerce datasets can save weeks of scraping.
Read article →
Real-Time RAG in Python: Feed Your LLM Live Google Results (2026)
What if your RAG pipeline could pull fresh web context right before generating an answer? A step-by-step guide to building a live search retrieval layer with Bright Data's SERP API and Python.
Read article →
Kafka vs Pub/Sub in 2026: When Managed Messaging Saves a Fintech Launch
A 2026 fintech messaging case study: how a Kafka backlog, broker disk pressure, and rebalance storm broke checkout, and why Google Cloud Pub/Sub moved the payment flow out of the danger zone.
Read article →
Python Web Scraping Without Proxy Management: Bright Data Web Unlocker API (2026)
The hard part is not parsing HTML. It is getting a usable response from modern protected websites in the first place. A step-by-step guide using Bright Data Web Unlocker API with Python and BeautifulSoup.
Read article →
SQL Query Optimization in 2026: 7 Simple Techniques for Faster Database Performance
Seven practical SQL query optimization techniques for faster database performance, with PostgreSQL-focused examples for joins, IN lists, EXISTS, date ranges, aggregates, and deduplication.
Read article →
FAQ
What is your data engineering background?
Are you available to hire?
How do we start working together?
Is your data layer keeping up?
From slow queries to fragile pipelines and large-scale collection, I help teams build data systems that stay fast and correct at scale.
See data engineering services →